

2025年4月15日
項目反応理論への招待:組織の解像度を上げるアンケートのポイントと分析(セミナーレポート)

ビジネスリサーチラボは、2025年3月にセミナー「項目反応理論への招待:組織の解像度を上げるアンケートのポイントと分析」を開催しました。
組織サーベイや適性検査の活用は、近年ますます進んでいます。その中で、「このアンケート内容で、組織や従業員を正確に測定できているのか?」と悩む方々も数多くいることでしょう。
こうした疑問に対して有効な分析手法が 「項目反応理論(IRT: Item Response Theory)」 です。IRTを用いることで、捉えたい概念をひとつひとつの質問項目がうまく測定できているかが詳しく検証できます。組織の状態をより正確に捉える質問項目を、IRTで洗練できるのです。
IRTを知ることで、「従業員エンゲージメントを測る質問項目の中で、特に有効なものはどれか?」「このアンケートは、従業員のどういった状態を捉えるのに向いているのか?」「一部の質問項目が、特定の層に偏った影響を与えていないか?」といった問いに、データから答えを導くことができます。
本セミナーでは、人事・組織の実務に役立つIRTの基本概念をわかりやすく解説し、どのようにサーベイの精度向上に活かせるのかを具体的な事例とともにお伝えしました。「なんとなく作成したアンケートの限界を突破したい」「もっと精度の高い組織サーベイを実施したい」そうお考えの方に、おすすめの内容です。
※本レポートはセミナーの内容を基に編集・再構成したものです。
項目反応理論が取り上げる関心
能渡:
本セミナーは、項目反応理論と呼ばれる分析手法について解説していきます。近年、組織サーベイや適性検査の活用はますます広がる中、多くの方は、「このアンケート内容で、本当に組織や従業員を正確に測定できているのか?」といった疑問や不安を抱いているかもしれません。
こうした悩みに有効な分析手法が、項目反応理論(IRT: Item Response Theory)です。IRTを使うと、それぞれの質問項目が測定したい概念をどれだけうまく捉えられているかを詳細に検証できます。組織の状態をより精密に把握するための項目の精度向上に役立つのです。
まずは、項目反応理論がどのような問題に焦点を当てているかについて、具体例を交えて見ていきましょう。例えば、ある会社が従業員の「関係スキル」を把握して改善策を考えるため、サーベイを実施したとします。ここでは、関係スキルを「人とうまく関係構築する能力」と定義したとしましょう。そのサーベイの項目として以下の3項目を作ったとします。これらについて、それぞれ「1:あてはまらない、2:あまりあてはまらない、3:少しあてはまる、4:あてはまる」の4種の選択肢で回答を求める構成を取った状況です。
- 出社したら周囲に挨拶する
- 仕事中、相手に突然話しかけない
- 退社時、周囲に一声かけてから帰る
さて、関係スキルを測定するこれら3項目を見て、皆さんはどう感じるでしょうか?おそらく、多くの方が「内容が簡単すぎるのではないか?この内容では、誰でも「あてはまる」と解答するのでは?」と感じたかと思います。
これら3項目の内容は、確かに「人とうまく関係構築する」うえでは必須の行為・スキルでしょうが、社会人ならほとんど誰もが職場マナーとして行うレベルの行為です。このような項目では、高い関係スキルを持っている人、普通の人、低い人がいたとしても、皆が「あてはまる」と答えてしまい、回答に差がつかずスキルの違いを把握できません。

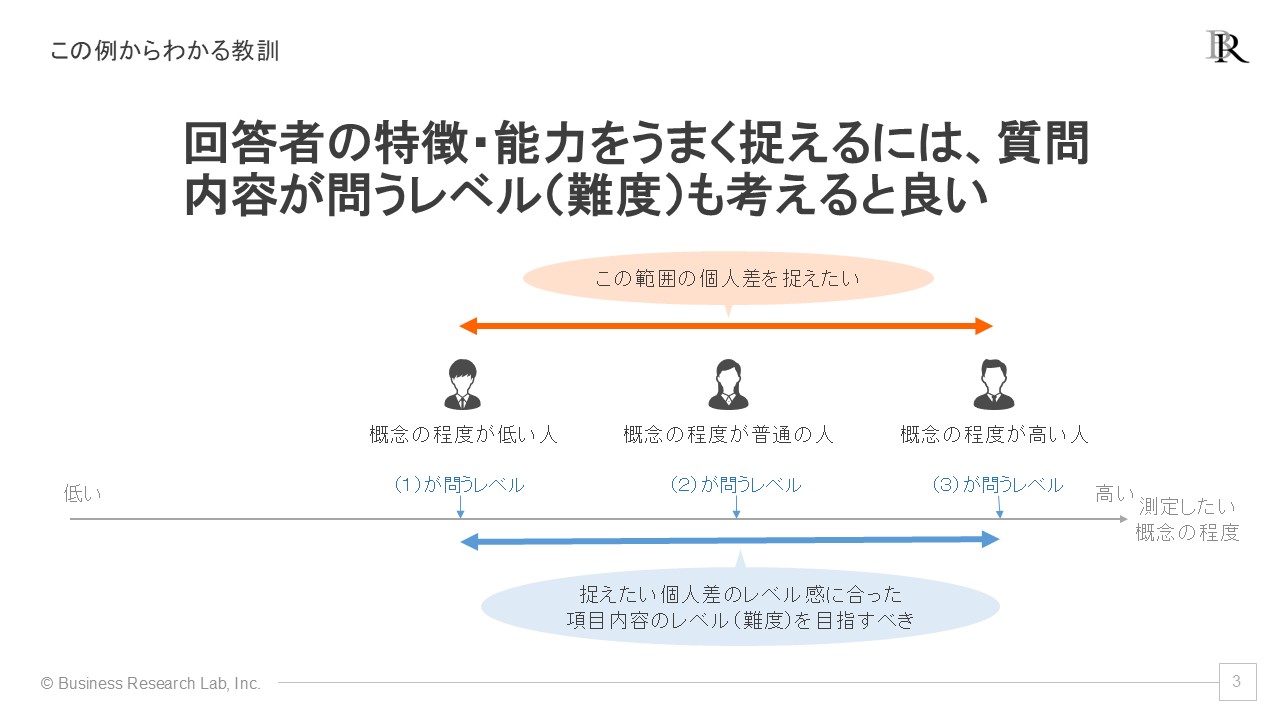
このような問題は、多くの方が直感的にご理解いただけることでしょう。これを心理測定の領域で捉え直すべく、イメージ図を出します。「関係スキルを測定しよう」とサーベイ設計時に考えているならば、従業員間でスキルの程度・レベルに違いがあることを想定しているはずです。
それに対して、先ほどの3項目はそのスキルレベルの違いを捉えられる次元の難度になっていないことが問題です。3項目それぞれが捉えているスキルの程度の範囲が、測定したい従業員たちのスキルレベルより低い状態にあります。こうなると、各項目が問うスキルレベルを全回答者が大きく越しているわけですから、彼らはすべての項目に「あてはまる」と最大限肯定的な回答をしてしまい、本来あるスキルレベルの差異が回答に表れないわけです。

この問題から学べる教訓は「サーベイで測定したい従業員の特徴や能力、レベルをうまく捉えるには、質問内容(項目)が問うレベル(難度)も考えた方が良い」ということです。測定したい概念について、捉えたいレベル感・程度に焦点を当てた項目に整えることが、組織の状態をうまく測定するうえで重要になってきます。
項目反応理論は、このような問題を統計的に分析し、改善のためのヒントを提供する分析枠組みです。具体的には、各項目がどの程度のレベル(難度)を捉えることができるのかを推定します。例えば、「学習意欲」の項目が実際に学習意欲の高低をうまく区別できているか、あるいはどの程度のレベルの学習意欲を測定するのが得意なのかを、詳細に分析できます。
項目反応理論を活用すると、各質問項目の測定性能が具体的な数値やグラフで明らかになり、測定精度の向上を図れます。さらに、この分析を発展的に応用することで、項目の取捨選択、複数のサーベイ項目間の統合・比較、より正確なスコアの作成、あるいは回答者の属性による測定性能の違いの検証など、多様な分析が可能になります。
まとめると、項目反応理論が取り上げる主な関心は、「質問項目が回答者の状態や能力レベルを正しく捉えているか」という点にあります。項目反応理論を用いることで、項目ごとにうまく捉えられる能力範囲が明確になり、その知見をサーベイ設計の精度向上に活かせるのです。
項目反応理論とは何か
それでは、ここからは項目反応理論とは何かを具体的に説明していきます。この分析がどういったものなのか、どういった出力が得られて、どんな数値が示されるのか。それらを見ることで何がわかるのかといった概要を解説していきます。
項目反応理論は、先ほど述べた通り「測定したい概念について、各項目が回答者のどういった状態を捉えているのか」を統計的に分析する枠組みです。特に、複数の項目(最低でも3項目)でひとつの概念を測定している状況において、この分析が使えます。
各項目の特徴をグラフで捉える:項目特性曲線
この分析で得られる代表的な出力に「項目特性曲線」と呼ばれるグラフがあります。これは、項目ごとに「回答者のレベル(能力や意識の高さなど)に応じて各選択肢がどの程度の確率で選ばれるか」の対応関係を推定したグラフです。選択肢ごとに対応関係が示されるため、選択肢の数だけ曲線グラフが示されます[1]。
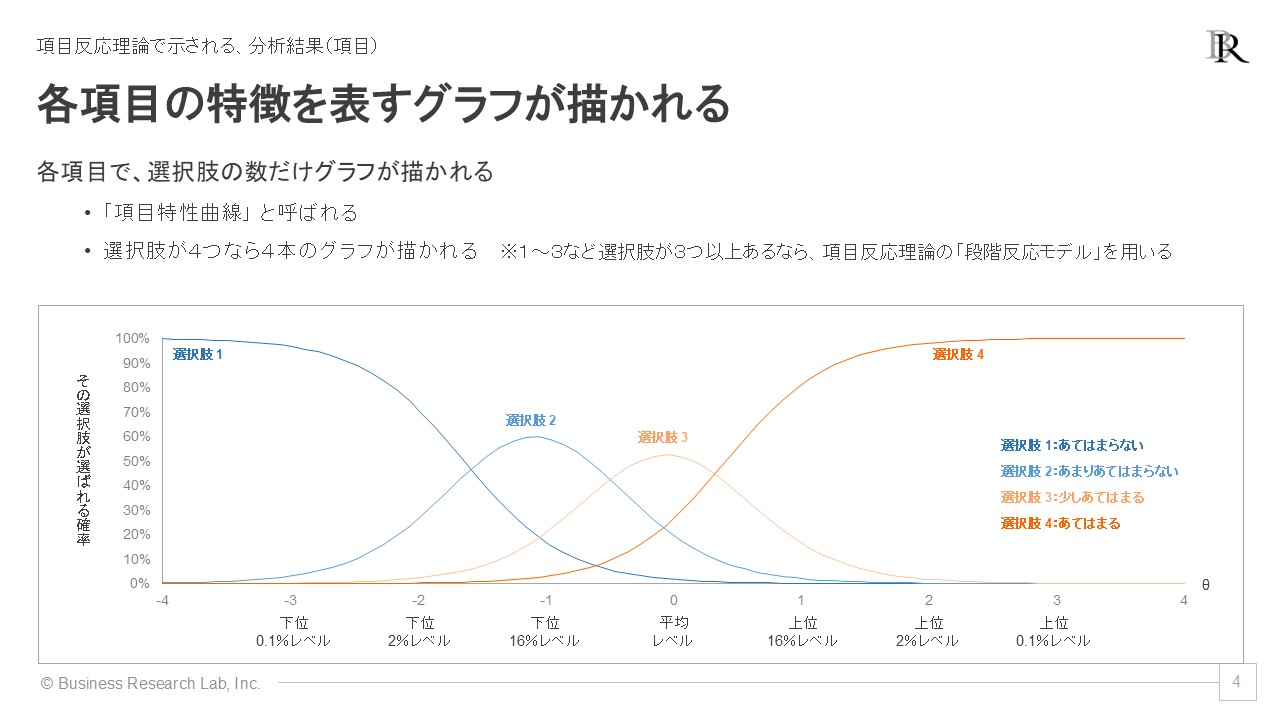
項目特性曲線のグラフの横軸は「潜在特性(θ)」と呼ばれる指標で、測定したい概念の程度・レベルを取ります。潜在特性はz得点と呼ばれる平均0、標準偏差1になるよう調整された得点であり、0点が平均的な程度の従業員を指します。そして、θが1点台だと上位16%レベルの高さ、2点台だと上位2%レベル、3点台だと上位0.1%レベルと解釈できます[2]。そして縦軸には「その選択肢が選ばれる確率」を取ります。このグラフにより、サーベイに回答する従業員において、測定したい概念の程度に応じて、どの選択肢を選びやすいのかが可視化されます。
架空例として、学習意欲を複数項目で測定した状況において、ある項目「仕事成果を高めるような知識を把握する」について項目反応理論の項目特性曲線を見てみましょう。
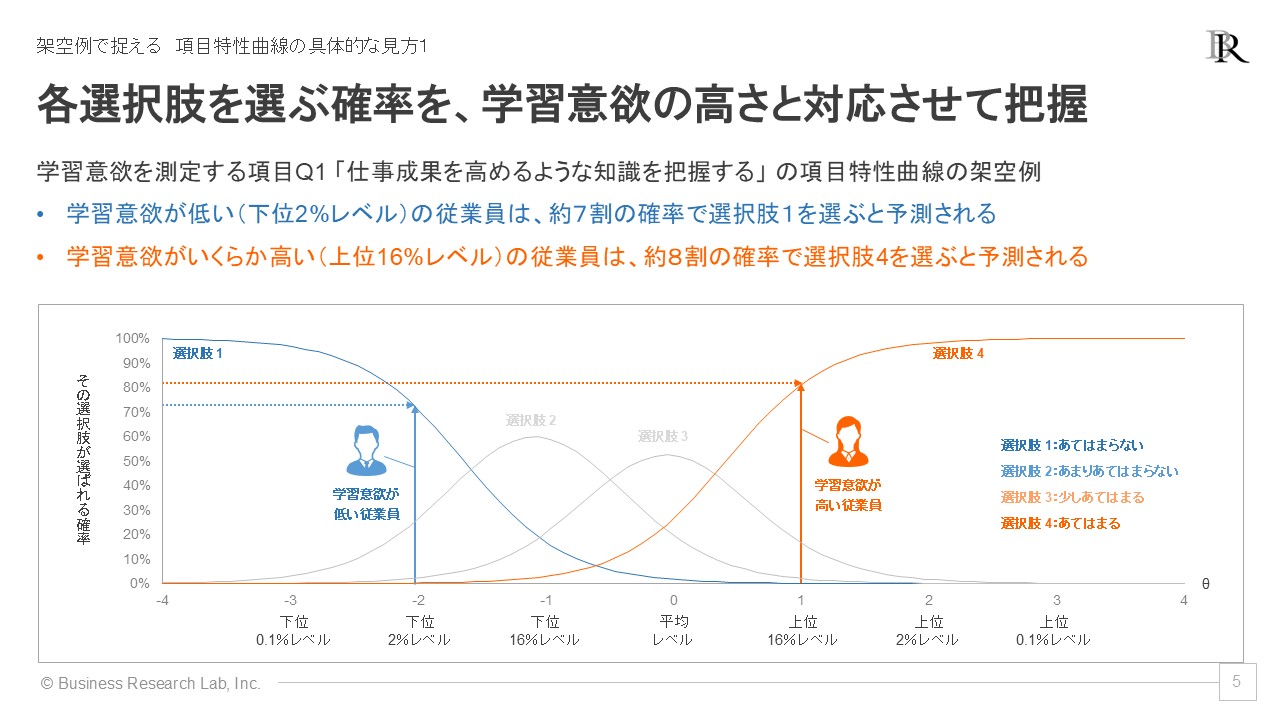
グラフを見ると、学習意欲が低い(下位2%レベル)の従業員は、「あてはまらない」という選択肢を70%の確率で選ぶことが予測されます。一方、学習意欲が高い(上位16%レベル)従業員は、「あてはまる」を80%の確率で選ぶことが示されています。このようにして、測定したい概念の程度・レベルに応じてある選択肢がどの程度の確率で選ばれるか、項目特性曲線から読み取ることができます。
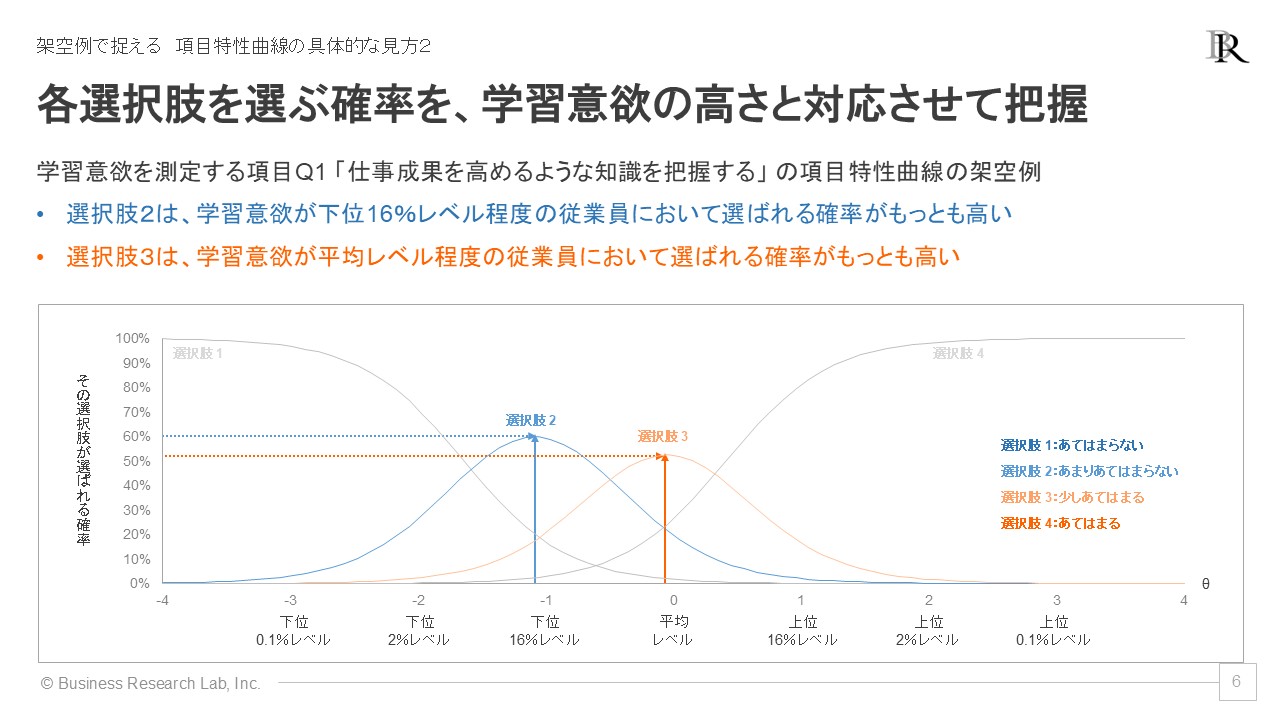
また各選択肢のグラフに注目すると、選択肢2(「あまりあてはまらない」)は学習意欲が下位16%程度の従業員に、選択肢3(「少しあてはまる」)は平均レベル程度の従業員に選ばれる確率が最も高くなることがわかります。回答者の特徴に応じた各選択肢の選択確率のみならず、ある選択肢を選びやすいのはどういった従業員なのかも、グラフから把握できるわけです。
とはいえ、「選択する確率がわかって、何が嬉しいんだろう?」と気になる方もいらっしゃるでしょう。ここまでグラフの読み取り方を説明しましたが、このグラフに表れる項目の特徴こそ、サーベイにおいて有用な情報となります。それは「その項目がうまく測定できる回答者の状態・レベルを把握できる」ことです。
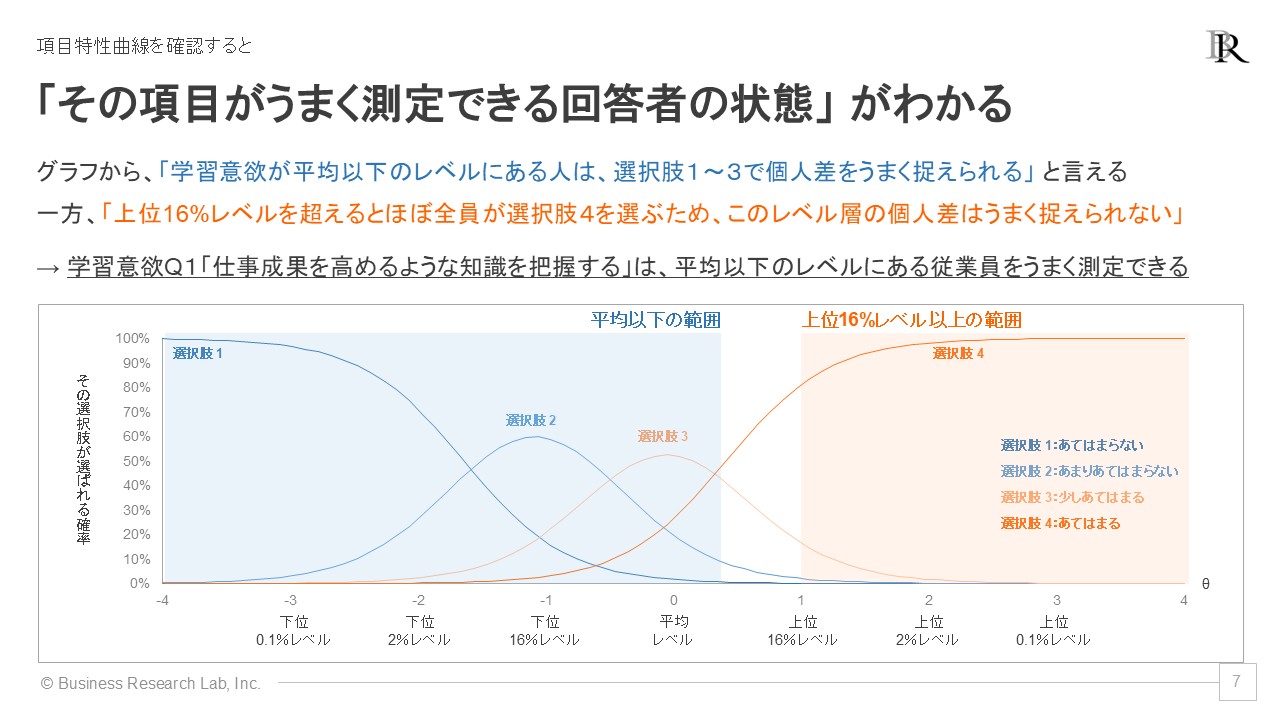
先ほどの項目特性曲線を見返すと、測定したい概念のレベルについて、平均より低い程度の範囲に山が多く存在しています。例えば、平均レベルなら選択肢3,下位16%レベルなら選択肢2、下位2%を下回るレベルなら選択肢1が選ばれやすいことがグラフから読み取れます。
この特徴から、この項目は「測定したい概念の程度が平均レベルより低い従業員をうまく測定できる項目だ」ということができます。「平均レベルなら3、少し低いレベルなら2、かなり低いレベルなら1の選択肢を選ぶ」と、レベルの低さに応じて回答選択に変化が生じると考えられます。
一方、上位16%を超えるレベルの高い従業員については、違いをうまく捉えられないこともわかります。測定したい概念の程度が上位16%以上と高いレベルの従業員は皆選択肢4を選ぶ確率が高いことをグラフは示しています。言い換えると、上位16%を超えるレベルなら、上位10%以上だろうが上位1%だろうが皆が「4:あてはまる」を選ぶため、「この項目では、高いレベル層にいる従業員の程度の違いを判別できない」わけです。
このようにして、項目特性曲線を見ることで、各項目がどういった回答者の状態・レベル感を捉えるのが得意かを把握できます。これとサーベイの目的を照らし合わせることで、各項目がサーベイにおいて有効に機能しているか、さらなるヒントが得られるのです。
各項目の特徴を数値で捉える:識別力と困難度
項目反応理論では、こうした項目特性曲線の特徴を数値化するために、「識別力」と「困難度」という2つの指標(パラメタ)が推定されます。識別力は、項目が測定したい状態をどれだけ明確に区別できるかを示す指標です。識別力が高いと回答者の状態ごとに選ばれる選択肢が明確に分かれますが、識別力が低い項目ではどの状態の回答者も同じような選択肢を選ぶ可能性があり、測定精度が低くなります。通常、識別力は最低限0.65以上、1.35を超えると十分に高いとされます。
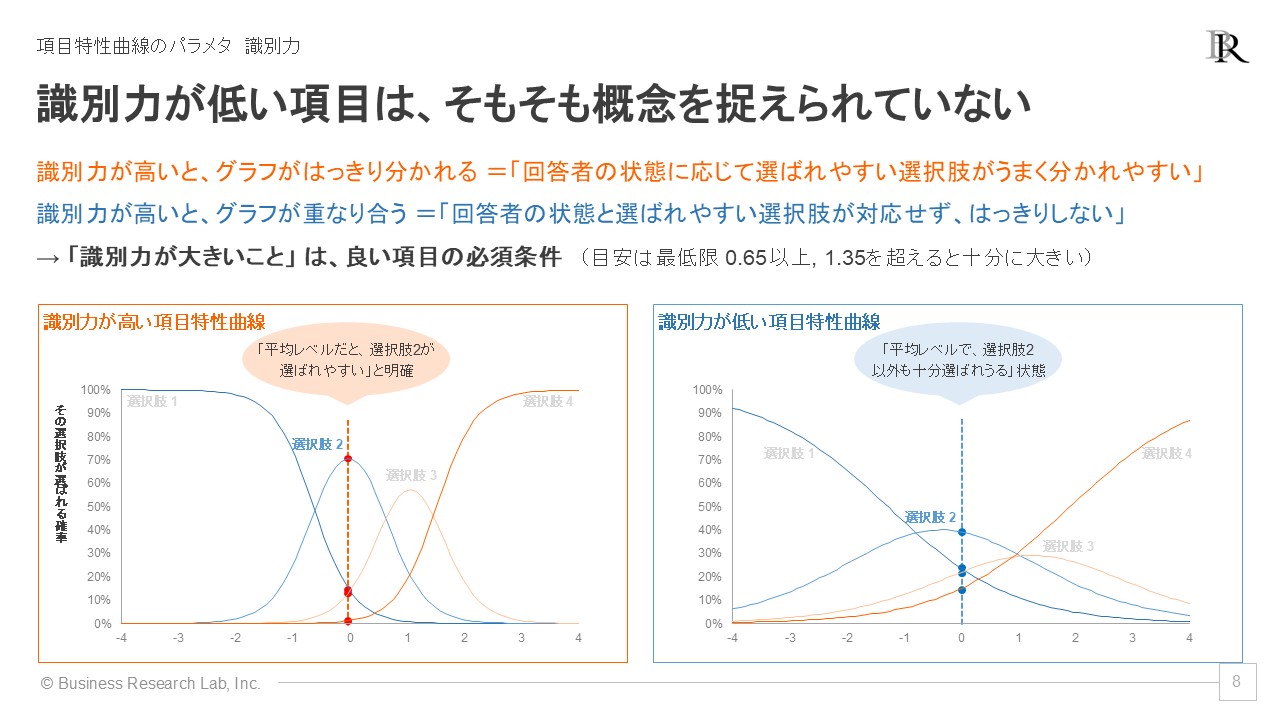
識別力が項目特性曲線のグラフにどう表れるかを見てみましょう。識別力が高い項目は、各選択肢の山が急になっています。これは、「測定したい概念の程度に応じて、特定の選択肢が選ばれる確率がはっきり分かれている」状態を表します。
識別力が高いと、例えばグラフにあるように「概念が平均レベルだと選択肢2を選ぶ可能性が高い」と、傾向がはっきり見えてきます。他方、識別力が低いグラフを見ると、各選択肢の山がなだらかです。平均レベルでは選択肢2を選ぶ確率は最も高いですが、その確率は約40%であり、他の選択肢を選ぶ確率は約10~20%と、そこそこあります。つまり識別力が低い項目は、回答者の状態やレベルに対して選ばれやすい選択肢がはっきりせず、回答者の状態と回答内容がうまく対応しない可能性が高いわけです。
次に困難度は、測定したい概念のどの程度のレベルを捉えるのに適しているかを示す指標で、4種の選択肢があるなら4個と選択肢ごとに推定されます。困難度が全体的に高い項目は、レベルや能力が高い層をうまく測定でき、困難度が低い項目は低いレベル層の測定に適しています。
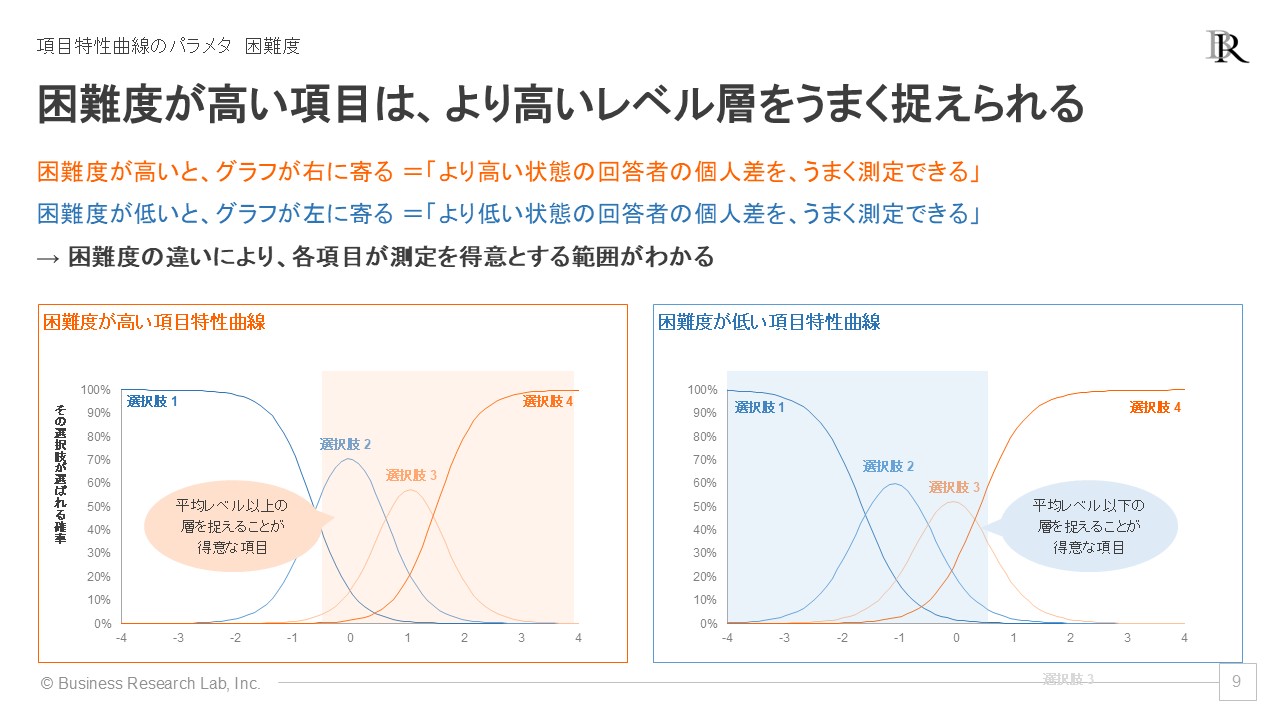
困難度が項目特性曲線にどう表れるかを見ると、困難度が高い項目のグラフでは、グラフの山全体が右側によっています。各選択肢のグラフが平均レベル(横軸の値が0)より右側に集中しており、「平均レベルを超える回答者の違いを、選択肢2~4で捉えられる」ことがわかります。つまり、困難度が高い項目は、高いレベルにある従業員の違いを捉えるのが得意だということです。
逆に、困難度が低いグラフは、グラフの山全体が左側によっています。「平均レベルを下回る回答者の違いを、選択肢1~3で捉えられる」とわかり、困難度が低い項目は、低いレベルにある従業員の違いが得意だとわかります。このように、識別力と困難度を見ることで、項目ごとの特徴をおおまかに把握できます。可能ならば項目特性曲線のグラフを見て詳しく判断すべきですが、簡便にはこれらの指標で各項目の測定精度やうまく捉えられるレベル層を知ることが可能です。
項目全体の測定性能をグラフで捉える:テスト情報関数
また、複数の項目を合算した得点、つまり項目全体による測定精度も検証できます。ここまでは各項目の特徴・測定性能を選択肢ごと検証する方法を見てきましたが、多くのサーベイでは、各項目を合算した得点や指標で測定したい概念を捉えます。項目反応理論では、その「各項目を合算した得点」の測定精度を検証する手続きも存在します。この精度を示すグラフを「テスト情報関数」と呼びます。
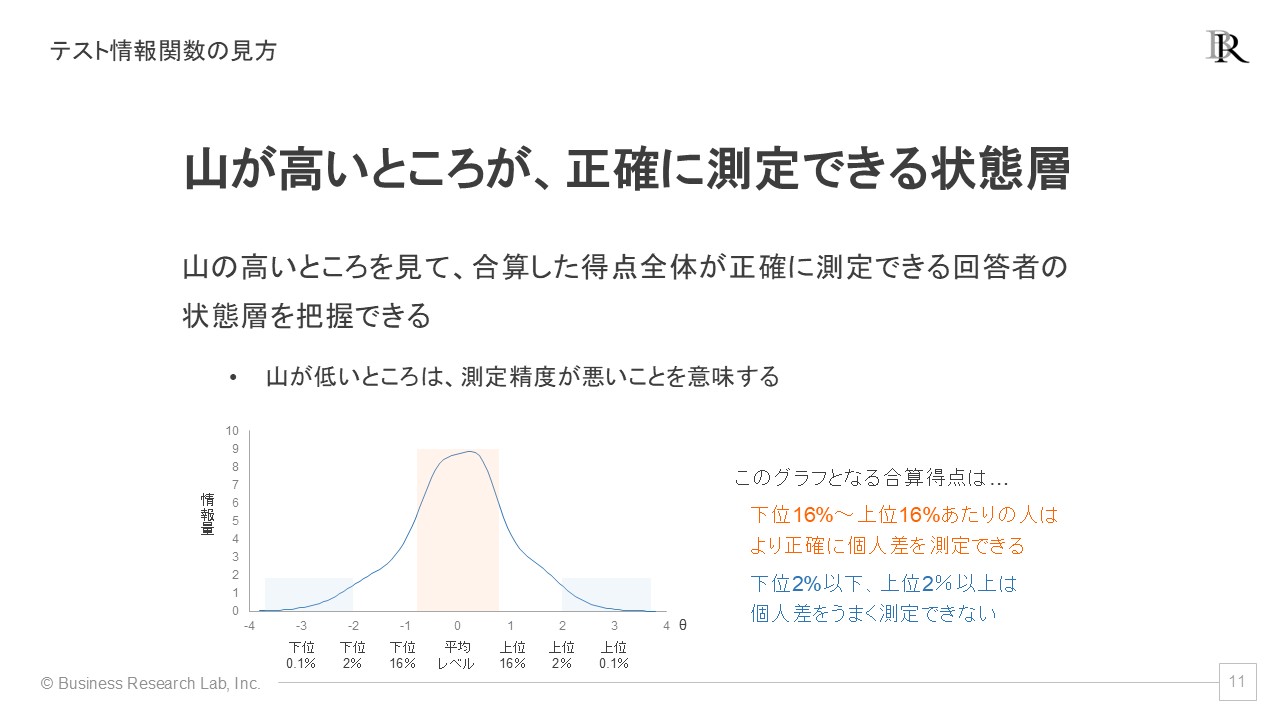
テスト情報関数は、横軸は項目特性曲線と同様に回答者の状態・レベルを表す指標である潜在特性(θ)を取ります。縦軸は「情報量」と呼ばれる指標で、ある回答者の状態・レベルを誤差なく正確に捉えられる程度を数値で表したものです[3]。つまり、グラフの山が高いところが「その得点が正確に測定できる回答者の状態・レベルの範囲」となります。
上の例では、下位16%~上位16%の範囲で、グラフの山が高くなっています。このことから、このテスト情報関数になった指標は「下位16%~上位16%の範囲にある従業員をより正確に測定できる、この範囲にいる従業員の測定が得意だ」と読み取ることができます。
一方、上位・下位2%を超える範囲は山が低いことから、この指標は「極端な範囲にいる従業イんを正確に測定できない」こともわかります。このように、合算した得点全体がどの層を特に正確に測定できるかをテスト情報関数からつかみ取ることができ、項目反応理論を用いるメリットとなります。
さらに発展的な活用として、性別や年代などの属性が違っても各項目の測定性能が同等かを「特異項目機能(DIF: Differential Item Functioning)」を検証して評価できます。これにより、サーベイ項目の測定性能が従業員の属性によって違いがないか評価できます。さらには、同じ概念を測定するアンケートの項目間で測定性能を比較し揃えることで、同一の得点基準による得点化を可能とする「等化」といった分析も可能です。これを用いれば、測定内容が異なる尺度でも同じ得点基準で従業員を評価でき、同じ概念を測定しているならば、異なるアンケートでも得点が比較できるようになります。
他にも項目反応理論には、様々な発展的な解析手法があります。組織サーベイの測定精度や信頼性を高め、さらなる活用を進めることができるのです。
人事データ分析における項目反応理論の適用場面
はじめに
伊達:
項目反応理論は、質問項目と回答者の特性を数理モデルで表現できる手法です。心理統計学の分野で研究されてきましたが、人事領域にも適用は可能です。ここでは、項目反応理論が人事領域のデータ分析にどのように活用できるのかを具体例を交えながら紹介します。
概念の精度検証
組織サーベイでは、「エンゲージメント」「組織コミットメント」「心理的安全性」など概念を測定することがあります。しかし、質問項目によっては実際に測定している内容が曖昧だったり、別の要素が混ざっていたりする可能性があります。
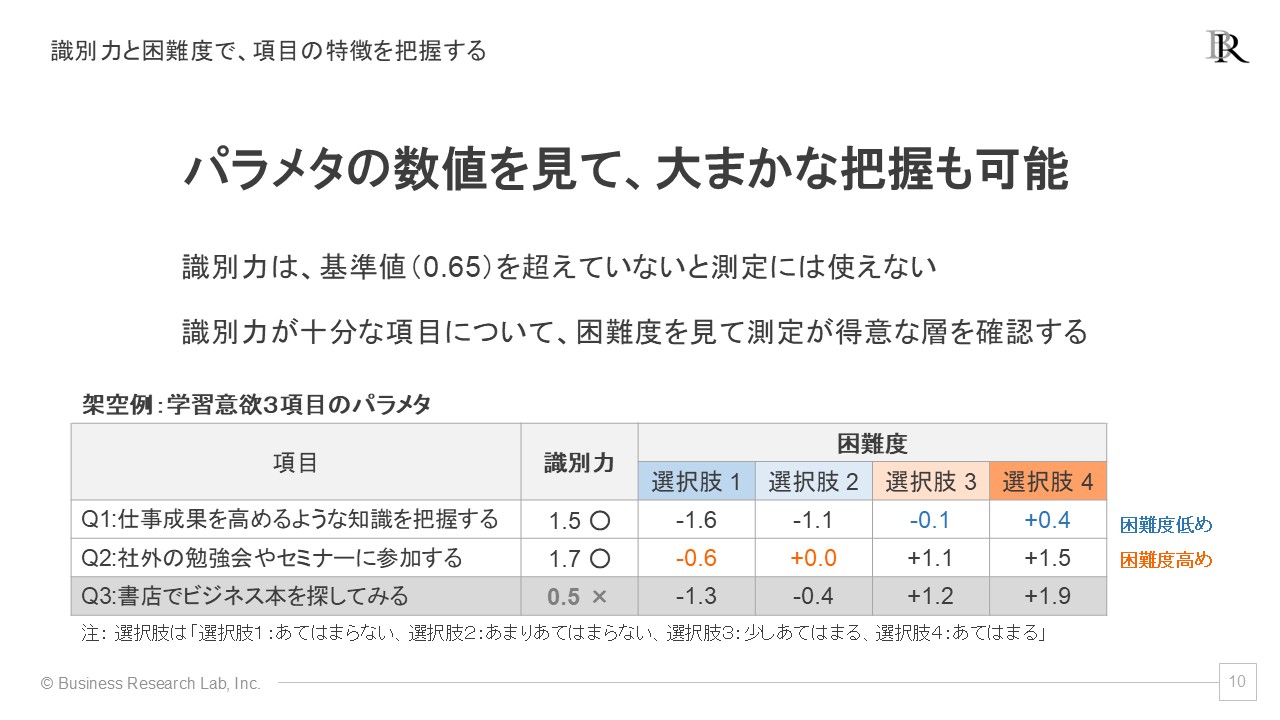
このような場合、サーベイで使っている複数の質問項目について、項目反応理論モデルを適用します。各項目の「識別力」と「困難度」を推定し、質問項目ごとに評価を行います。識別力が低い項目は、測定対象と回答傾向がうまく対応していない可能性が高いと言えます。また、困難度に重なりがある項目同士は、測定内容が互いに似すぎて重複しているかを見極める必要があります。
例えば、組織コミットメントを測る5つの質問があるとします。しかし分析してみると、ある1つの質問(「会社のイベントには必ず参加している」など)は識別力が低いことがわかりました。その項目を削除・修正することで、より正確に組織コミットメントを把握できるようになります。
複数回答形式の検証
「0:まったくあてはまらない~4:非常にあてはまる」などの多肢選択式の組織サーベイは、回答が極端に偏る、あるいは中立が多すぎるなどの問題が起きやすいものです。また、選択肢数が多いとき、各選択肢が本来想定した概念レベルをきちんと区別できていない可能性があります。
このような状況では、段階反応モデルを用いて、選択肢ごとにどのレベルの潜在特性に対応するかを推定します。例えば「0(まったくあてはまらない)」を選ぶのはどのレベルの特性までなのか、そこから「1, 2, 3, 4」と選ばれる確率が上がるのはどこか、という形で曲線を描きます。
この分析によって、5段階にしているが実質3段階しか機能していないなどの問題を把握できます。また、例えば「4:非常にあてはまる」が、実は平均より少し高いレベルでも選択されるなど、思ったよりハードルが低い選択肢になっていることを把握することも可能です。
得点化の方法の見直し
従来の得点化においては、各項目のスコアを単純に平均することが多いでしょう。しかし、項目ごとに難易度や回答傾向が異なる場合、単純合計は実際のレベルを正しく反映していない恐れがあります。極端に答えやすい項目ばかりで高得点になってしまうなど、偏った集計結果が出る可能性があります。
項目反応理論の推定手法を使い、潜在特性得点を算出することで、この問題に対処できます。それぞれの項目で回答した選択肢のパターンから、その人の「真のレベル」を数値化する手順を踏みます。各項目の識別力・困難度も考慮されるため、単純な平均よりも精度が高い得点が得られます。
項目反応理論による得点化のメリットは、例えば、困難度が高い項目でより肯定的な選択肢を選んだ場合は潜在特性のレベルが高いと推定されやすいなど、「項目の特性」を加味してスコアが計算される点です。
同一概念を扱う複数サーベイの統合
同じ企業でも、時期や目的が異なる複数のサーベイで、ほぼ同じ概念を測っている場合があります。しかし、質問形式や選択肢、回収方法が異なると、結果を横並びで比較・統合することが難しくなります。サーベイをまたいだデータ分析を行いたいが、測定スケールが違うと合算や比較ができないという問題に直面します。
このような場合、項目反応理論を用いることで、異なるサーベイ間の尺度を単一の潜在特性尺度にマッピングすることが可能です。例えば、一部の質問項目が共通する場合、それらの項目をアンカーとして分析を行い、潜在特性上で両サーベイの得点を合わせられます。「サーベイAの得点が高い=サーベイBの得点も同じくらい高い」という関係を、項目パラメータを推定することによって作り出すことができます。
このアプローチにより、サーベイを実施した方法や選択肢が違っても、項目反応理論モデルを使えば同じ概念の潜在特性スコアに変換可能になります。また、部門や年度をまたいだ大きなデータを使って、一括で分析できるようになります。
例えば、昨年度は「1~5段階」でエンゲージメントを測ったが、今年度は「0~4段階」で尋ね、しかも質問文も若干変えたというケースを考えてみましょう。これら2種のアンケートに回答する協力者を募り、項目反応理論の共通受験者を用いた等化を行えば、昨年度と今年度の結果を同じ潜在特性スケールに載せて比較可能になります。
国際比較の項目検証
グローバル企業で、同じサーベイを多言語展開した場合、言語や文化的背景の違いで「あてはまる」と答えやすい/答えにくいなどの偏りが発生します。国ごとの回答傾向(例えば、日本は控えめ、米国はポジティブに回答しやすいなど)によって、単純比較がミスリーディングになる可能性があります。
各国・地域ごとに同じ項目について項目反応理論分析を行い、特異項目機能(Differential Item Functioning;DIF)の検出をすることで、この問題に対処できます。DIFがあれば、「同じ潜在特性レベルでも、国や文化によって肯定率が違う項目」があることを示唆します。DIFが大きい項目は、国際比較スコア計算から除外・修正する、もしくは国別のパラメーでそれぞれ得点計算して比較する必要があります。
例えば、「業務に対して主体的に取り組んでいる」という項目に対し、実は欧米の従業員は中程度でも肯定しやすい一方、日本やアジアでは厳しめに答える傾向があり、DIFが生じていたとします。項目反応理論を用いて項目パラメータを各国で推定してそれに基づいた得点を計算することで、真の主体性の差を国際比較できるようになります。
パルスサーベイの項目最適化
パルスサーベイは高頻度・短時間で実施するため、項目数が少なく設定されることが一般的です。その分、どの項目を選ぶか次第で測定精度が左右されます。項目が少ないため、回答が偏ったり、測定範囲が限られたりして、狙い通りに組織の状態を把握できないこともあります。
項目反応理論を用いて、事前に候補となる項目の識別力・困難度を推定することで、より効果的なパルスサーベイが設計できます。「広範囲の特性レベルをカバーしつつ、識別力の高い項目」を優先的にピックアップするのです。項目数を絞った「短縮版サーベイ」を作成しても、項目反応理論に基づいて選んだ項目であれば精度を保ちやすくなります。
この手法の利点は、項目数が少ないままでも、なるべく多くの情報を引き出せる最適な項目セットを組めることです。例えば、毎週1回だけ実施する「今週の満足度」サーベイを計画する際、候補10項目を項目反応理論で分析して、識別力が高く、困難度の異なる3項目に厳選します。その結果、要点を押さえた質問だけで組織の変化を追跡できるようになります。
研修後テストの分析
研修で実施される理解度テストでは、問題が易しすぎて差がつかない/難しすぎて全員が誤答する、といった問題が起きます。また、合否ラインの決定や、どの程度の知識が身についたかを正確に把握できない場合もあります。
そこで項目反応理論分析を行い、困難度と識別力を推定することで、テストの品質を向上させることができます。困難度が適切な問題は、一定以上の知識レベルを持つ受講者だけが正解を得られるため、試験としての判別力が高くなります。また、識別力が高い問題は、正解者と不正解者が明確に分かれ、受講者の真の理解度を良く弁別します。
反応スタイルの個人差を統制する
同じ概念を問う組織サーベイでも、個人差として「常に高めに回答する人」「常に厳しめに回答する人」「中立を選びやすい人」がいます。こうした反応スタイルの違いは、真の特性と混ざってしまい、実態を正しく測定できないという問題があります。
項目反応理論モデルでは、複数項目の回答パターンを総合して潜在特性を推定するため、単一の項目だけでは捉えきれないバイアスをある程度は補正できます。さらには、推定するパラメータを追加することで、反応スタイルそのものを別の潜在因子としてモデリングし、回答バイアスと測定したい概念を分離して推定する手法もあります。
このアプローチによって、単純合計だと極端反応の影響が大きいところを、項目反応理論による潜在特性推定は複数項目の整合性をチェックするため、ある程度の補正が利くようになります。また、回答スタイルが違うだけで本来同じレベルの特性を持つ従業員が、違う得点になってしまう事態を避けられます。
例えば、「会社の評価に不満はない」を5段階で答えると、ポジティブ選択をしやすい従業員は全部4や5を選んでしまいます。項目反応理論によって別の項目の回答との整合性を見ながら潜在特性を推定すると、従業員の回答全体から本音に近いスコアを推定できるようになります。
コンピテンシー評価の設計
コンピテンシーモデルを社内で定め、行動特性を評価する設問を設けることがあるかもしれません。各項目がどれだけ正しく「段階的な行動レベル」を見極められているか不透明なことがあります。そこで、コンピテンシーを「潜在特性」と捉え、各行動指標を項目反応理論で分析することで、より効果的な評価が可能になります。
困難度が異なる項目の存在、例えば、「基本業務を期限内に行う(低難易度)」と「業務改善のため新たな仕組みを自発的に導入する(高難易度)」など、行動レベルが違う項目を可視化できます。これによって、「初心者の行動~熟達者の行動」を網羅し、かつ各段階の行動を適切に見極める質問がそろうようになります。
おわりに
項目反応理論は、心理学・教育学の分野で発展してきた理論ですが、人事領域においても大きな可能性を秘めています。企業が従業員の声をより正確に把握し、人材育成や組織改善につなげていくためには、従来の方法に加えて、項目反応理論のような高度な分析アプローチも検討する価値があるでしょう。
Q&A
Q:項目反応理論を適用するにはどれくらいのデータが必要でしょうか。属性ごとの不均衡にも対応できるのでしょうか。
能渡:
項目反応理論を使う際に推奨されるサンプルサイズは、研究上では500名ほどとされています。最低限としては250名以上がひとつの目安になる場合もあります[4]。もっとも、これは選択肢が複数個あるときに用いる段階反応モデルを適用する際の目安です。また、推定が大雑把になりますが、データを加工して2パラメタ・ロジスティックモデルを用いるなど調整することで必要なサンプルサイズを少し緩和することも可能です。
属性ごとの不均衡についても対応が可能です。ただし、属性の偏りが大きい場合は推定にバイアスが生じている懸念がありチェックする必要があります。例えば、特異項目機能の検証などで、人数差があるグループ間の推定値に偏りがないかを確認する方法が挙げられます。
Q:これからエンゲージメントサーベイを設計する際に、どのように識別度や困難度を確認すれば良いでしょうか。
伊達:
本日ご紹介した項目反応理論の分析は、基本的にデータを取得した“後”に実施する枠組みです。アンケートを取ってから、「この項目は想定どおりの困難度や識別度になっているのか」を検証する、という流れになります。
能渡:
困難度については、サーベイ設計にて項目を作るときにある程度狙いをつけるが可能です。例えば、「ハイパフォーマーの人だけ“あてはまる”と答えそうな、レベルの高い内容を含む設問を作ってみよう」「これは最低限の基準をクリアしているかを確認するための、簡単な項目にしよう」といった具合に、困難度の程度を意識しながら設計することには意味があります。そうした仮説に基づいて項目を作り、実際にデータが集まった段階で項目反応理論を用いて、想定どおりの困難度になっているか検証するという流れです。
伊達:
特に困難度が特定の範囲に偏っていないかどうかを考慮するのは大切ですよね。
能渡:
はい、困難度が特定の範囲に集中してしまうと、測定したいグループの上位(あるいは下位)の特性をうまく識別できない場合もあります。設計段階でも「どの層を測りたいか」を意識しながら項目を設定することは大切です。あるいは、様々な従業員の特徴を幅広く捉えたいならば、ほとんどの人が「あてはまる」と答えそうな困難度が低めの項目、平均的な従業員なら「あてはまる」と答えそうな困難度が中程度の項目、ハイレベルな従業員のみ「あてはまる」と答えそうな困難度が高めの項目を、まんべんなく含める方針が考えられます。
Q:項目反応理論では潜在特性を推定するということですが、因子分析などによるスコアとはどう違うのでしょうか。
能渡:
因子分析も個人の潜在特性をスコア化することはできます。しかし、項目反応理論の場合は「各選択肢」に着目し、その選択肢がどの程度の困難度(回答者の潜在特性がどのレベルか)を示すかを明示的に扱います。例えば、選択肢の1番は潜在特性が低い人ほど選びやすい、5番は潜在特性が高い人ほど選びやすい、という具合に数値化してモデルに組み込みます。これによって、より精密に個人の潜在特性を推定できる可能性が高まります。
因子分析の場合、選択肢1から5までを “等間隔”とみなすことが多いため、選択肢ごとの困難度の違いを充分に拾いきれないところがあります。因子分析による得点化も良い方法ですが、より精度を高めたい場合には、項目反応理論のほうがより適していると考えられます。
脚注
[1] 「はい/いいえ」「参加/不参加」といった回答を求める項目やチェックボックスなど、データ値が2種になる2値データの場合はグラフが1つのみ出力されます。これは、2値データと架空例のように複数選択肢を取るデータで項目反応理論における計算方法が異なるためであり、代表的なものとして、2値データの場合は2パラメタ・ロジスティックモデル、複数選択肢のデータは段階反応モデルと呼ばれる方法を用いて計算がされます。
[2] この割合は、標準正規分布における割合と一致しています。潜在特性は測定したい概念の程度・レベルに関する母集団分布が標準正規分布になるよう近似計算されるため、標準正規分布の割合が使えるという仕組みです。
[3] 情報量は「1/標準誤差^2」の数式と表すことができ、ここでいう標準誤差は「ある潜在特性の人々を何度も測定した際に、それらの測定値が平均的にどの程度ばらつくか」を意味します。この数式から「情報量が大きいほど標準誤差は小さくなる」ことがわかり、情報量が大きい潜在特性θの範囲では測定値がばらつきにくく、θの大きさを正確に測定できることを表すといえます。
[4] この推奨サンプルサイズは、下記の文献を参照しています。
Embretson, S. E. & Reise, S. P. (2000). Item Response Theory for Psychologists. Lawrence Erlbaum Associates.
登壇者
 伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
神戸大学大学院経営学研究科 博士前期課程修了。修士(経営学)。2009年にLLPビジネスリサーチラボ、2011年に株式会社ビジネスリサーチラボを創業。以降、組織・人事領域を中心に、民間企業を対象にした調査・コンサルティング事業を展開。研究知と実践知の両方を活用した「アカデミックリサーチ」をコンセプトに、組織サーベイや人事データ分析のサービスを提供している。著書に『60分でわかる!心理的安全性 超入門』(技術評論社)や『現場でよくある課題への処方箋 人と組織の行動科学』(すばる舎)、『越境学習入門 組織を強くする「冒険人材」の育て方』(共著;日本能率協会マネジメントセンター)などがある。2022年に「日本の人事部 HRアワード2022」書籍部門 最優秀賞を受賞。東京大学大学院情報学環 特任研究員を兼務。
 能渡 真澄
能渡 真澄
株式会社ビジネスリサーチラボ チーフフェロー。信州大学人文学部卒業、信州大学大学院人文科学研究科修士課程修了。修士(文学)。価値観の多様化が進む現代における個人のアイデンティティや自己意識の在り方を、他者との相互作用や対人関係の変容から明らかにする理論研究や実証研究を行っている。高いデータ解析技術を有しており、通常では捉えることが困難な、様々なデータの背後にある特徴や関係性を分析・可視化し、その実態を把握する支援を行っている。




{kind=link}