

2024年9月30日
人事データで読み解く離職の兆候と対策(セミナーレポート)

ビジネスリサーチラボは、2024年9月にセミナー「人事データで読み解く離職の兆候と対策」を開催しました。
突然の退職届。なぜ?どうすれば防げたのか?こんな経験はありませんか。人材の離職は組織に多大な影響を及ぼします。
そこで注目されているのが、人事データの活用です。データ分析によって、離職リスクを察知し、効果的な対策を講じることができます。
本セミナーでは、人事データを活用した離職予測と要因分析について解説します。データサイエンスの専門知識がなくても理解できる内容です。
※本レポートはセミナーの内容を基に編集・再構成したものです。
データに基づく予測と防止
本セミナーは、データ分析と離職抑制の融合をテーマとしています。具体的には、データの力を活用して、誰が離職しそうかを予測する方法と、どのように離職を効果的に減らすかを考えていきます。これらの観点から、企業が直面する人材流出の課題に対して、データドリブンなアプローチを探ります。
データ分析と離職抑制はともに、現在のビジネス界で注目を集めているトピックです。データ分析については、HRテクノロジーの進展により、人事関連のデータが蓄積されるようになりました。また、ピープルアナリティクスへの関心が高まっており、従業員の心理や行動を数値化し、分析する取り組みが増えています。
一方、離職抑制の観点からは、リテンション(定着支援)の重要性が議論されています。採用活動では成果を収めても、せっかく獲得した優秀な人材が退職してしまうという課題に直面している企業もあります。このような状況下で、いかにして従業員の定着率を向上させ、組織の成長を実現するかが重要になります。
離職指標の多様性
離職を予測し、防ぐためには、データ分析において2つの指標に注目する必要があります。一つは「離職」そのものであり、もう一つは離職の「要因」です。両者の関係性ですが、要因を原因、離職を結果として仮定しています。それぞれの指標について掘り下げることで、離職の予測と防止について理解することができます。
1つ目の指標である離職は、一般的に従業員が会社を辞めるという行動として理解されるものです。最もシンプルな形では、「辞めていない」状態を0、「辞めた」状態を1として、二値データで離職を表現することができます。この0と1のデータは、離職の有無を明確に示す意味で有用です。
しかし、現実の人間の心理や行動は、0か1かで割り切れるものではありません。その間には様々な段階、つまりグラデーションが存在します。例えば、まだ辞めていないものの、辞めたいと強く思っている人もいれば、そうした思いがほとんどない人もいます。0に近い状態の人もいれば、1に近い状態の人もいるのです。
この「辞めたい気持ち」の度合いは、離職意思と呼ばれ、離職をめぐる指標となり得ます。離職したかどうかの0/1データだけでなく、離職意思も分析に取り入れることで、より良い予測や対策が可能になるかもしれません。離職の分析において0/1データのみを使用している企業もありますが、離職意思も有益なので、測定し活用することをお勧めします。
ただし、「離職したい気持ちがある」ということをアンケートで尋ねると、従業員の間に不安や動揺を引き起こす可能性があります。そのような場合、「今の会社で働き続けたいと思う」など、肯定的な表現で質問し、その回答を逆転処理することで離職意思を推測する方法もあります(ただし、定着意思と離職意思は厳密には異なる概念であることを念頭に置いておく必要があります)。
さらに、離職への近さだけでなく、積極的かつ肯定的な状態で会社に残っている人々にも注目しましょう。例えば、仕事に生き生きと取り組んでいる人や、組織に強い愛着を持っている人などです。
こうしたポジティブな態度や感情の度合いも、重要な指標として活用することができます。これらの指標を総合的に分析することで、離職を防ぐだけでなく、従業員のエンゲージメントを高め、組織全体の活性化につながる施策を立案することが可能になります。
筋の良い離職要因の必要性
離職の予測と防止を検討する上で、2つ目の指標は要因です。これは、従業員が会社を辞める原因となる要素を指します。皆さんは、従業員がどのような理由で辞めると考えますか。この問いへの回答が、離職の要因となります。要因を把握することは、離職問題に取り組む上で重要です。
要因の精度は、離職対策の成否を左右します。適切な要因を特定し、それを正確に表すデータを活用することができれば、離職の予測精度が向上し、対策も立てやすくなります。逆に、不適切な要因を選択してしまうと、分析の精度が低下し、有効な対策を講じることが困難になってしまいます。
もしかすると、「あらゆるデータを要因とみなして、どんどん分析に投入すれば良いのではないか」と考える人もいるかもしれません。しかし、この方法は必ずしも成功につながるとは限りません。
データ分析の世界では、「ガベージイン・ガベージアウト」という格言があります。これは、質の悪いデータを入力すれば、質の悪い結果しか得られないという意味です。無計画にデータを集めても、有益な洞察は得られにくいのです。
また、データを分析に投入するためには、事前にデータを整備する必要があります。このプロセスには相応の時間と費用がかかります。有効性が不明確なデータを整備することは、効率性の観点から望ましくありません。
実際、データ整備に膨大なリソースを投じたにもかかわらず、期待した成果を得られなかったデータ分析プロジェクトが数多く存在します。こうした失敗を避けるためにも、分析対象とする要因の選定は慎重に行う必要があります。
そうなると、離職予測に有効な「筋の良い要因」を特定することが大事になりますが、これが意外に難しい課題となります。なぜでしょうか。それは、適切な要因を選定するためには、知識と経験が必要だからです。思いつきで要因を挙げても、分析の質は高まりません。精度の高い予測と効果的な対策を実現するためには、信頼できる経験則や、学術的な知見を参照しなければなりません。
離職研究の学術的知見から
離職の要因は非常に多岐にわたります。ここでは、データを用いた離職の予測と防止を検討する際の参考として、学術的な知見の一部を紹介します。ただし、これらはあくまで一部の知見であり、他にも様々な要因があるうえ、全ての状況に当てはまるものではないことにご注意ください。
初めに、組織コミットメントは、古くから離職と強い関連があることが実証されてきました。様々な業種を対象にした研究においても、業種を問わず、組織コミットメントが離職と密接に関連していることが明らかになっています[1]。組織コミットメントが低い従業員は、会社に対する愛着が弱いため、離職を考える傾向が強くなります。
人間関係も離職に影響を与えます。組織内で良好な関係が築けていれば、それが離職を抑制する要因となります。逆に、人間関係が良くない場合、離職が促進される可能性が高くなります。特に内部ネットワーキング、つまり組織内での関係構築は重要です[2]。良好な内部ネットワークは、仕事に必要な情報へのアクセスを容易にし、周囲との良好な関係を通じて組織への心理的な結びつきを強めます。
仕事の性質も離職の要因となります。例えば、仕事の要求が高い場合(業務量が多い、納期が厳しいなど)や、仕事のコントロールが低い場合(自分で仕事の進め方やペースを調整できないなど)は、離職リスクが高まります[3]。
組織の変革に対する従業員の態度も、離職に影響を与えます。変革を脅威と感じない従業員は離職しにくい傾向にあります。逆に言えば、変革を脅威に感じると離職が促進されます。ポジティブな変革志向(自分が変革に対処できるという自信、変革に対する前向きな姿勢、変革に自分が影響を与えられるという感覚)や、変革に関連する公平性(変革において成果が公平に分配されている感覚、変革プロセスが公平であると思うこと、マネージャーが従業員を公正に扱っていること)が重要です[4]。
興味深いことに、個人の特性によって離職の要因が異なる場合もあります。例えば、自分の行動や主張を状況に応じて調整できるセルフモニタリング能力の高い人は、仕事満足度が離職の主要な要因となります。一方、セルフモニタリング能力が低い人は、組織コミットメントが離職の主要な要因となることが示されています[5]。
また、思いがけない要因が離職に影響を与えることもあります。例えば、過去の離職経験が次の離職決定に影響を与えます。過去に離職した際に「会社に残っておけば良かった」と後悔した経験がある場合、次の離職決定により慎重になります[6]。これは、ネガティブな感情を避けようとする心理が働くためだと考えられています。
さらに、突発的な出来事が離職の引き金となることがあると指摘されています[7]。仕事のオファー、家族の健康問題、職場におけるコンフリクト、組織の方針転換、人事異動、配偶者の転勤などが例として挙げられます。職務不満だけでなく、予期しないショックが離職につながる可能性があることを表しています。
重回帰分析による離職リスク予測
離職と要因という2つの指標について掘り下げてきました。では、これらの指標を用いて、どのように離職を「予測」するのでしょうか。離職予測には様々な方法がありますが、ここではシンプルな方法である重回帰モデルによる予測の考え方を紹介します。
重回帰分析は、広く用いられている統計分析の手法です。この分析から得られる重回帰式を活用することで、離職を複数の要因で予測することができます。重回帰式は、組織サーベイなどの回答データをもとに算出できます。重回帰分析を行うことによって、例えば次のような重回帰式が得られます。
Y=b0+b1X1+b2X2+b3X3+e
この式において、Yは予測したい変数である離職意思を表します。X1、X2、X3は離職に影響を与える要因で、例えばX1を仕事の自律性、X2を周囲からの支援、X3を上司のリーダーシップとします。ここにおいて、Yは離職に関わる指標、X1、X2、X3は要因に関わる指標です。
式の中のb0は切片と呼ばれ、すべての要因が0の時の成果指標(この場合は離職意思)の予測値を表します。eは誤差項で、重回帰モデルで説明できない変動や測定誤差を指します。
一見複雑に見える式ですが、離職を複数の要因で予測しているものです。b1、b2、b3は偏回帰係数と呼ばれ、各要因に対する重みを示します。離職との関連が強い要因ほど、対応する係数の絶対値が大きくなると理解すれば良いでしょう[8]。
重回帰モデルによる予測の実際の活用方法は、次のようになります。
- 既存データを用いて重回帰式を求める
- 四半期に1回など定期的に、組織サーベイで要因のみを簡易に測定する
- 得られた回答を重回帰式に代入し、離職の予測を行う
ここで重要なのは、予測には精度があるということです。重回帰式を構成する要因でどの程度正確に離職を予測できるかを表す指標があります。重回帰分析では、これを決定係数(R2)と呼びます。決定係数は0から1の間の値をとり、1に近いほどモデルの説明力が高いことを意味します[9]。逆に、決定係数が小さい場合、選択した要因ではうまく離職を予測できていないということになります。
また、重回帰モデルは要因が原因、離職が結果という因果関係を仮定していますが、これはあくまで仮定にすぎません。重回帰分析の結果が直接的に因果関係を証明するわけではありません。
因果関係の検証には、時系列でデータを集めて丁寧に分析するなど(他にも様々な条件を満たす必要があります)、さらに踏み込んだ方法が必要になります。こうした追加的な検証を行わないと、予測の精度に不安が残る可能性もあります。
重回帰モデルはシンプルな予測方法ですが、これを出発点として、より複雑で精緻な予測モデルへと発展させていくこともできます。ただし、モデルが複雑になるほど解釈が難しくなるため、実務での活用においては予測精度と解釈可能性のバランスを考慮しましょう。
離職防止策の立案方法
離職の予測に関しては、より高度な手法を用いて取り組んでいる企業も、少数ながら存在します。しかし、そうした企業で浮上してきているのが、例えば「この部署には辞めそうな人が多い」という予測結果が出ても、「どうすれば良いのかわからない」という問題です。
特に、予測の際に複雑なアルゴリズムを用いると、この問題はより顕著になります。何が要因なのかが不明確になるため、状況が悪化していることはわかっても、具体的な対策を講じることが困難になってしまうのです。
本セミナーで私が要因の精度が大事だと強調したのは、それが対策の精度にもつながるからです。データを大量に投入して予測の精度を上げても、要因が判別できなければ、効果的な対策を検討することができません。
さて、対策を考える上で重要になるのは、「関連性」と「スコア」という二つの要素です。これらを組み合わせることで、対策の切り口を得ることができます。
まず、関連性とは、離職とそれぞれの要因との間の関係のことを指します。データ分析を行うことで、離職を表す指標と、ある特定の要因の間に統計的に有意な関連があるかを判断することができます。また、その関連の強さも数値化することが可能です。
先ほど説明した重回帰分析では、偏回帰係数が関連の強さを示す指標となります。偏回帰係数が統計的に有意であれば、その要因と離職の間に関連があると見ることができます。
具体例を挙げましょう。離職に関連する指標として離職意思を設定し、その要因として、仕事の自律性、周囲からの支援、上司のリーダーシップの3つを設定して重回帰分析を行ったとします(サンプルサイズは500とします)。この分析から、次の結果が得られました。
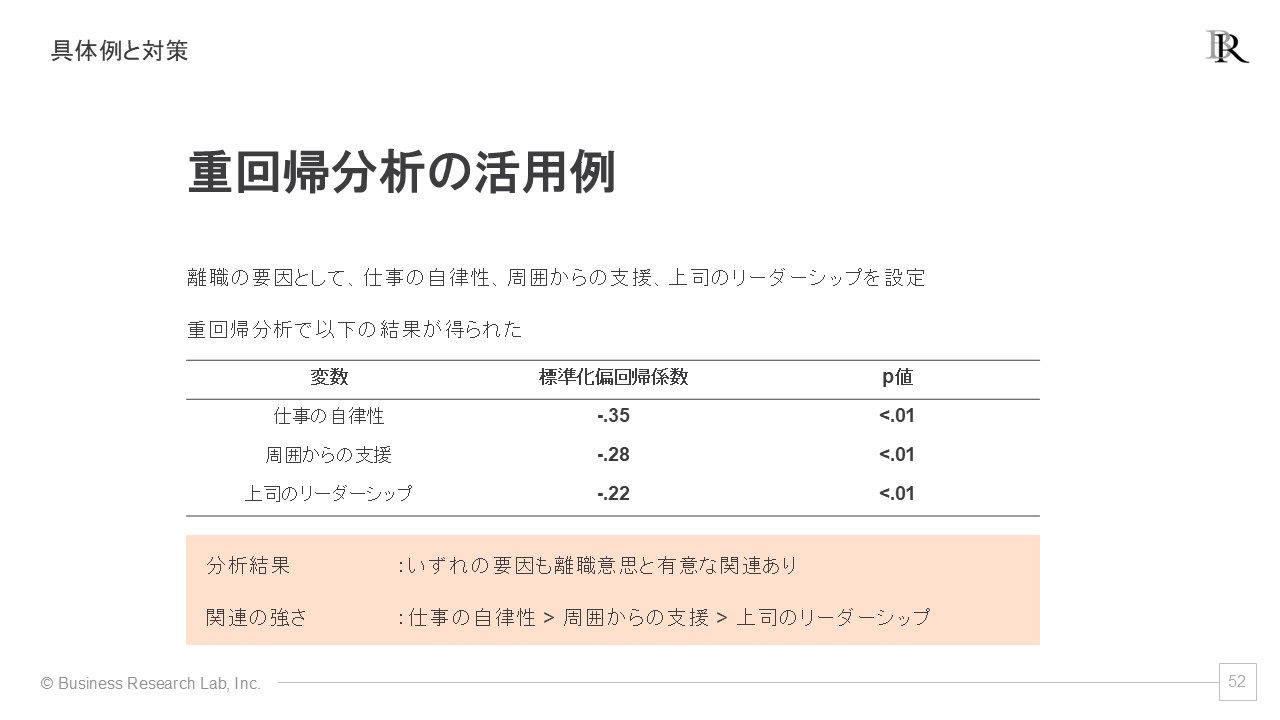
この分析における決定係数は.38で統計的に有意であり、これは選択した要因で離職意思の分散の38%を説明していることを意味します。人と組織をめぐる現象としては、これは決して低くない値です。
分析結果を見ると、いずれの要因も離職意思との間で有意な関連が認められています。標準化偏回帰係数の絶対値を比較すると、仕事の自律性>周囲からの支援>上司のリーダーシップという順で関連の強さが示されています(標準化しているため、比較が可能です)。
この結果から、次のような解釈ができます。
- 仕事の自律性が高い人ほど、離職意思が低い傾向にある
- 周囲からの支援が多い人ほど、離職意思が低い傾向にある
- 上司のリーダーシップが効果的であると感じる人ほど、離職意思が低い傾向にある
これらの解釈を基に、対策を考えることができます。まず最も効果が期待できるのは、仕事の自律性を高めることです。具体的には、従業員に仕事を思い切って任せる、いわゆるデリゲーション(権限委譲)を実践することが考えられます。
誰にどの仕事を任せるのかを検討し、任せるためのコミュニケーションをとりましょう。そして、一度任せたら口を出さず、従業員の自主性を尊重することが大切です。
リソースに余裕があれば、周囲からの支援や上司のリーダーシップの改善にも取り組むと良いでしょう。周囲からの支援を高めるには、職場開発の取り組みが有効です。例えば、チームビルディングやメンタリングの導入などが考えられます。上司のリーダーシップについては、リーダーシップ開発の実施や、定期面談の導入などが効果的かもしれません。
このように、データ分析から得られた関連性の情報を基に、対策を立案することが可能になります。ただし、これらの対策はあくまで例示であり、実際の適用に当たっては、各組織の特性や状況に応じて調整する必要があります。
要因の伸びしろへの注目
ここまで、離職と要因の「関連性」について説明してきました。しかし、離職との有意な関連が示されたからといって、すべての要因に対して同じように対策を講じることが適切とは限りません。対策を検討する際には、もう一つ重要な観点があります。それが「スコア」です。
スコアとは、各要因の現状の得点を指します。スコアの高低によって、その要因への対策の効果や必要性が変わってきます。スコアが低い場合は改善の余地、すなわち「伸びしろ」があると考えられますが、逆にスコアが高い場合は、それ以上の改善が難しいかもしれません。
具体例で考えてみましょう。仮に、仕事の自律性が1点から5点の間で評価されるとします。ある組織でこの得点が4.8点だったとします。これはかなり高いスコアであり、これ以上改善するのは非常に困難だと言えます。
一方で、同じ組織で周囲からの支援のスコアが2.3点だったとします。こちらは改善の余地があります。このような状況では、周囲からの支援を向上させるための対策を講じる方が、良い結果をもたらすでしょう。
ただし、注意すべき点もあります。仕事の自律性のスコアが高いということは、それがこの組織の強みであることを示しています。したがって、このスコアを維持することも重要です。高いスコアを維持するための取り組みも、忘れてはいけません。
要するに、離職防止策を考える際に注目すべき領域は、「関連性は強いが、スコアは低い」という特徴を持つ要因です。そのような要因に対策を講じることが改善につながります。
整理しましょう。離職防止策を検討する際には、関連性とスコアの両方を組み合わせて検討します。例えば、次の手順で考えることができます。
- 各要因と離職との関連性の強さを分析する
- 各要因の現在のスコアを測定する
- 関連性が強く、かつスコアが低い要因を特定する
- 特定された要因に焦点を当てた対策を立案する
Q&A
Q:離職予測の精度を向上させるためにどのような技術が活用できるでしょうか。例えばAIの活用は効果的でしょうか。
AIの活用が効果的な場合があります。例えば、テキストデータや行動データなど、非構造化データも分析に組み込むことができるかもしれません。多様な情報を予測モデルに取り入れることが可能になります。
しかし、注意点もあります。複雑なアルゴリズムを使用すると、モデルの解釈が難しくなる「ブラックボックス化」が起こる可能性があります。離職の要因を理解し、適切な対策を講じることが困難になる場合があります。
また、現在のデータに過度にフィットしてしまい、新しいデータに対する予測精度が低下する「過学習」のリスクもあります。AIを活用する際は、モデルの解釈可能性と汎用性のバランスを考慮することが重要です。
Q:離職の予測や防止を検討していく際に、個人情報保護やプライバシーの観点からどのような配慮が必要でしょうか。倫理的な問題は生じませんか。
個人情報保護とプライバシーへの配慮は非常に重要な課題です。例えば、データの匿名化を行い、個人を特定できないようにデータを処理することが考えられます。また、データへのアクセス権限を管理し、必要最小限の人員のみがデータを扱えるようにすることもあり得ます。
データの利用目的を明確にし、何のためにデータを使用するのか、また何には使用しないのかを明確にしましょう。データ利用の目的や方法について従業員に説明し、同意を得るようにしたいところです。
予測結果に基づいて一方的に判断するのではなく、従業員の自己決定を尊重することも大切です。特定の個人や属性に不当に不利な結果をもたらさないよう、モデルのアウトプットを慎重に検証する必要があります。
Q:離職の予測や防止を行っていく際、データを用いて行っていく際、従業員とのコミュニケーションはどのように行うべきでしょうか。離職の予測モデルの存在を公開すべきでしょうか。
従業員とのコミュニケーションは、離職の予測や防止を行う上で重要です。モデルの存在と目的について、従業員に対して誠実に説明することが求められます。隠し立てせずに情報を共有することで、信頼関係を築くことができます。
データ分析の目的が従業員のキャリア支援や職場環境の改善にあることを強調し、従業員の理解と協力を得るようにしましょう。個人情報の保護方法や、データの匿名化処理についても説明する必要があります。
ただし、個人レベルの予測結果を直接従業員に開示することは、逆効果になる可能性があるため、慎重に検討しましょう。代わりに、組織全体や部署レベルでの分析結果を共有し、改善策について議論する機会を設けるのも一案です。
Q:離職予測のモデルの精度を高めるためにどのようなデータを収集していくと効果的でしょうか。例えば従業員の行動データなど、アンケート以外の方法は有効でしょうか。
アンケート以外にも様々なデータを活用することができます。例えば、労働時間のデータや休暇取得率は、従業員の負担や仕事とプライベートのバランスを示す指標となります。社内コミュニケーションツールの使用頻度や内容も、組織における人間関係を示唆する可能性があります。
ただし、これらのデータを収集・活用する際は注意が必要です。収集するデータが実際に離職と関連しているかを慎重に検討する必要があります。意味のないデータを集めても、モデルの精度向上にはつながりません。また、特に行動データの収集は従業員のプライバシーに関わる可能性があるため、適切な取り扱いが求められます。
Q:離職の予測・防止に重回帰分析を活用する際、世代間や職種間での違いをどのように考慮すべきでしょうか。モデルの汎用性と個別性のバランスをどう取ればよいでしょうか。
初めに、全従業員のデータを用いて基本となるモデルを構築し、組織全体に共通する離職要因を把握します。その後、世代や職種ごとに係数が異なるのかを検討することができます。この方法によって、組織全体に適用可能なモデルを基礎としながら、世代や職種の特性を考慮に入れることが可能になります。
脚注
[1] Khatri, N., Budhwar, P., and Chong, T. F. (2001). Explaining employee turnover in an Asian context. Human Resource Management Journal, 11(1), 54-74.
[2] Porter, C. M., Woo, S. E., and Campion, M. A. (2015). Internal and external networking differentially predict turnover through job embeddedness and job offers. Personnel Psychology, 00, 1-38.
[3] de Croon, E. M., Sluiter, J. K., Blonk, R. W. B., Broersen, J. P. J., and Frings-Dresen, M. H. W. (2004). Stressful work, psychological job strain, and turnover: A 2-year prospective cohort study of truck drivers. Journal of Applied Psychology, 89(3), 442-454.
[4] Fugate, M., Prussia, G. E., and Kinicki, A. J. (2012). Managing employee withdrawal during organizational change: The role of threat appraisal. Journal of Management, 38(3), 890-914.
[5] Jenkins, J. M. (1993). Self-monitoring and turnover: The impact of personality on intent to leave. Journal of Organizational Behavior, 14(1), 83-91.
[6] Lee, H., and Sturm, R. E. (2017). A sequential choice perspective of postdecision regret and counterfactual thinking in voluntary turnover decisions. Journal of Vocational Behavior, 99, 11-23.
[7] Holtom, B. C., Mitchell, T. R., Lee, T. W., and Inderrieden, E. J. (2005). Shocks as causes of turnover: What they are and how organizations can manage them. Human Resource Management, 44(3), 337-352.
[8] 重回帰分析の詳細については、当社のコラムを参照していただければ幸いです。
[9] ただし、高い決定係数が必ずしも良い予測を意味しない点には注意が必要です。例えば、オーバー・フィッティングと言って、モデルがデータに過度に適合し、新しいデータに対する予測性能が低下する現象が生じ得ます。オーバー・フィッティングは、サンプルサイズに比べて影響指標が多い場合や、不必要に複雑なモデルを使用した場合に発生しやすくなります。
登壇者
 伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
神戸大学大学院経営学研究科 博士前期課程修了。修士(経営学)。2009年にLLPビジネスリサーチラボ、2011年に株式会社ビジネスリサーチラボを創業。以降、組織・人事領域を中心に、民間企業を対象にした調査・コンサルティング事業を展開。研究知と実践知の両方を活用した「アカデミックリサーチ」をコンセプトに、組織サーベイや人事データ分析のサービスを提供している。著書に『60分でわかる!心理的安全性 超入門』(技術評論社)や『現場でよくある課題への処方箋 人と組織の行動科学』(すばる舎)、『越境学習入門 組織を強くする「冒険人材」の育て方』(共著;日本能率協会マネジメントセンター)などがある。2022年に「日本の人事部 HRアワード2022」書籍部門 最優秀賞を受賞。東京大学大学院情報学環 特任研究員を兼務。



