

2024年1月9日
人事データ活用 基礎の基礎:分析に向くデータとは(セミナーレポート)

ビジネスリサーチラボは、2023年12月にセミナー「人事データ活用 基礎の基礎:分析に向くデータとは」を開催しました。
人事領域でデータ活用が進んでいます。HRテクノロジーに保存されたデータや、組織サーベイなど、多くのデータ源があります。
しかし、いざ分析しようとすると、「そのデータでは、思うように分析できない」ということが起こります。分析に向くデータもあれば、可能な分析方法が非常に制限されるデータもあるのです。
分析に向くのは、どのようなデータでしょうか。分析に向くデータを集めるには、どうすれば良いのでしょうか。
人事データ活用の基礎の基礎でありながらも、とても大事な知識かと思います。人事データ活用におけるデータの性質について解説しました。
※本レポートはセミナーの内容を基に編集・再構成したものです。
データの基礎の基礎の基礎
人事領域においてデータの重要性が高まっており、多くの企業がデータ分析に注目しています。しかし、実際にデータを分析しようとすると、思うように進まないことがあります。
その原因は様々なのですが、主要なものの一つは「データが適切に整備されていないこと」にあります。
データが不十分だと、望んだ分析を行うことができません。また、分析ツールを正しく使用できても、データの品質が悪いと誤った結果が出る可能性があります。データが不適切であると、分析結果の解釈も難しくなります。データの整備はデータ活用において重要な役割を果たします。
そこで、本日は「データの基礎の基礎」についてご紹介します。データの活用に関心を持ち、実践したことのある方にとっては、当たり前の話も含まれているかもしれません。しかし、今一度、確認していただきたいと思います。
さて、本当の意味での基礎についてお話しします。まず、データはCSVやExcelの形式で保存することが大切です。「さすがに、それは当然では」と思う方もいるかもしれません。
しかし、例えば、10年ほど前、組織サーベイや適性検査の結果を紙やPDF形式で提供され、「これを分析してください」と依頼されたことがありました。最近はこのようなケースは減っていますが、まだなくなったわけではありません。
次に、一つのセルには一つのデータを入力するようにしてください。複数のデータを一つのセルに入れないでください。
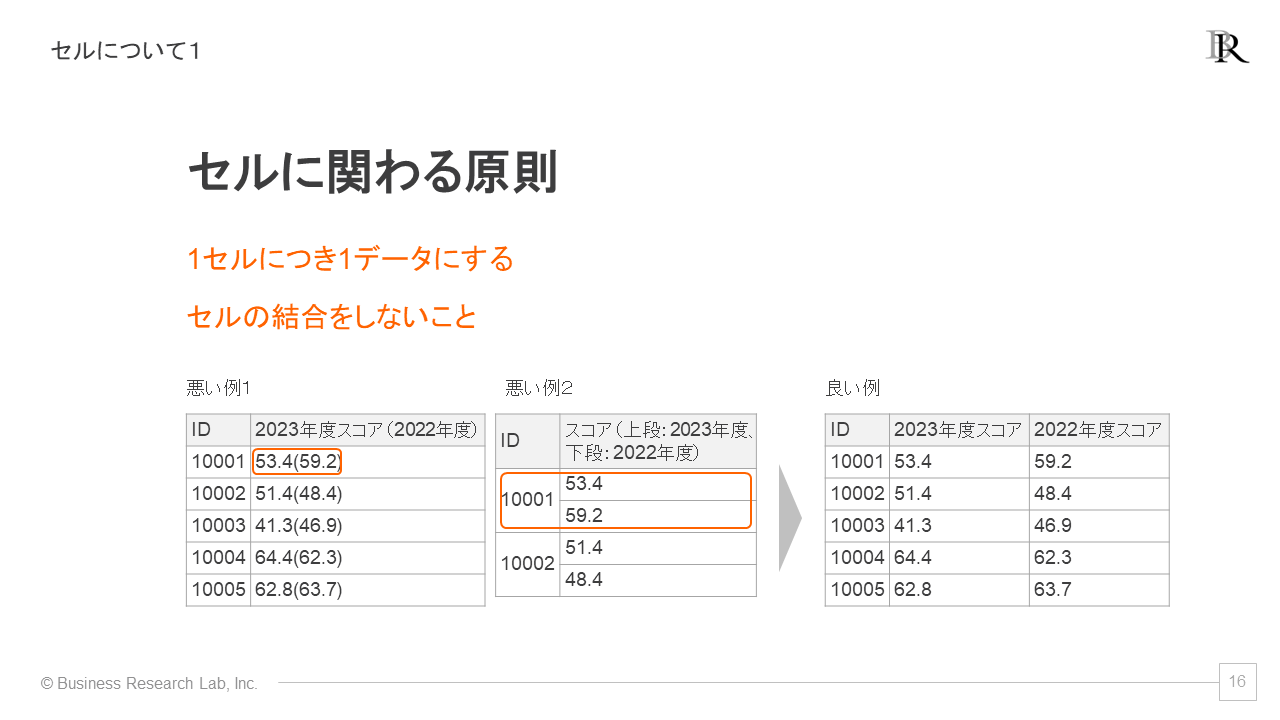
例えば、左側の「悪い例1」を見てください。このセルには、2023年度と2022年度のスコアが含まれています。目視での確認には問題ありませんが、分析を行う際には不適切です。
セルの結合も避けてください。これも見た目では問題ないかもしれませんが、データの読み込みにおいて問題が起きます。例えば、「悪い例2」では、IDのセルが結合されていますが、避けるべきです。
文字列の使用も避けるようにしてください。例えば、スコアに「点」はついていませんか。給与に「円」はついていませんか。データに単位が含まれてしまうと、データ分析が困難になります。
また、脚注をセルに含めると、適切にデータを読み取れなくなる可能性があります。例えば、ID番号5のデータに「62.8」というスコアの隣に脚注が入っています。データ作成時には文字列を極力避けましょう。

セル内でスペースや改行を入れないようにします。例えば、悪い例1では、スペースが入ってしまっています。これにより、データが正しく読み取れなくなることがあります。
一つのセル内にスコアを上下に分けて記入するのも、人間には理解しやすいかもしれませんが、適切に読み取らせることができません。

皆さんが直接整理したデータは大丈夫かもしれません。しかし、社内で使われている他のデータについても、これらの点を確認し、適切に処理するよう知識を共有していきましょう。
一貫性のある入力ルールを設定することも大切です。例えば、「部門名」の表記ゆれが見られることがあります。「情報システム部」と「情シス部」のように、同じ部門であるにもかかわらず異なる形式で記載されていることがあります。
日付データも同様です。和暦と西暦が混在している場合などがあります。これらもデータの読み取り時に問題を起こす可能性があります。

ここまでの点について、自社のデータには問題はなさそうだと思う方もいるかもしれません。ただ、複数のソースからデータを統合する際には、注意が必要です。例えば、健康管理部門のデータと人事部門のデータを統合する際、入力ルールが異なっていることがあります。
基本的すぎると感じた方もいる可能性がありますが、実際にはこれらの問題に直面することが少なくありません。当社も問題のあるデータを見たり、クリーニングしたりした経験があります。基本的な点をしっかり実践していきたいところです。
構造化されたデータ
次に、データがどのような形で整備・保存されていると良いのか、そのイメージをお伝えします。整然と構造化されたデータになっていることが大事です。具体的には、例えば、次のようなデータです。
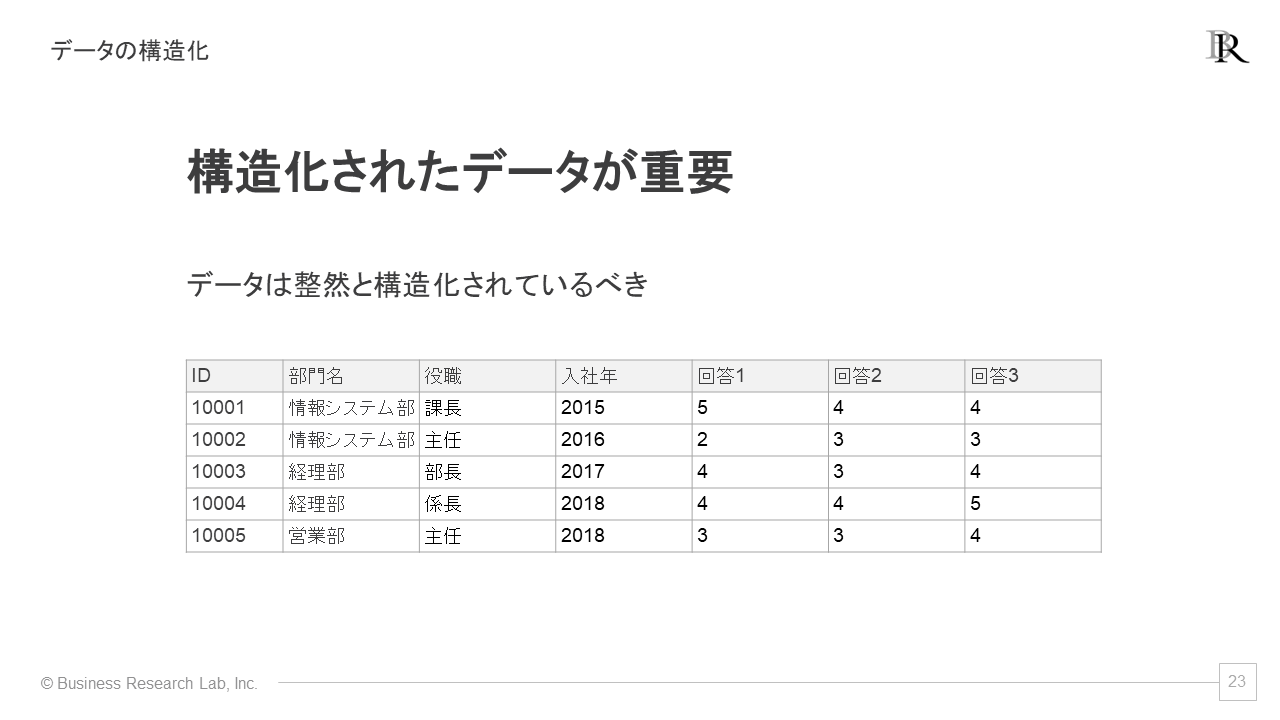
まず、「列」です。列にはどのような情報を入れるべきかというと、変数を配置します。変数とは、さまざまな数値やカテゴリーを取り得る項目のことです。例えば、部門名、役職、入社年、組織サーベイの回答1、回答2、回答3などが変数です。これらが列を形成します。
次に「行」ですが、行はケースを表します。例においては、個々のデータに相当します。10001というIDの方は、情報システム部の課長で、2015年に入社した、といった具合に行で、その人の情報が分かります。このようにケースが行を形成します。
つまり、変数が列を形成し、ケースが行を形成するのです。行と列が組み合わさった表が、構造化されたデータです。この構造を持っていないデータも多々あります。行と列を意識してデータを整備しましょう。
データの構造化についてさらに詳しく学びたい方は、整然データのことを調べることをお勧めします。整然データはハドリー・ウィッカムが提示した考え方です。
個人データと集計データ
個人データと集計データを便宜上分けて話をしましょう。後述するように、これらは実践上、重要な違いを持っています。
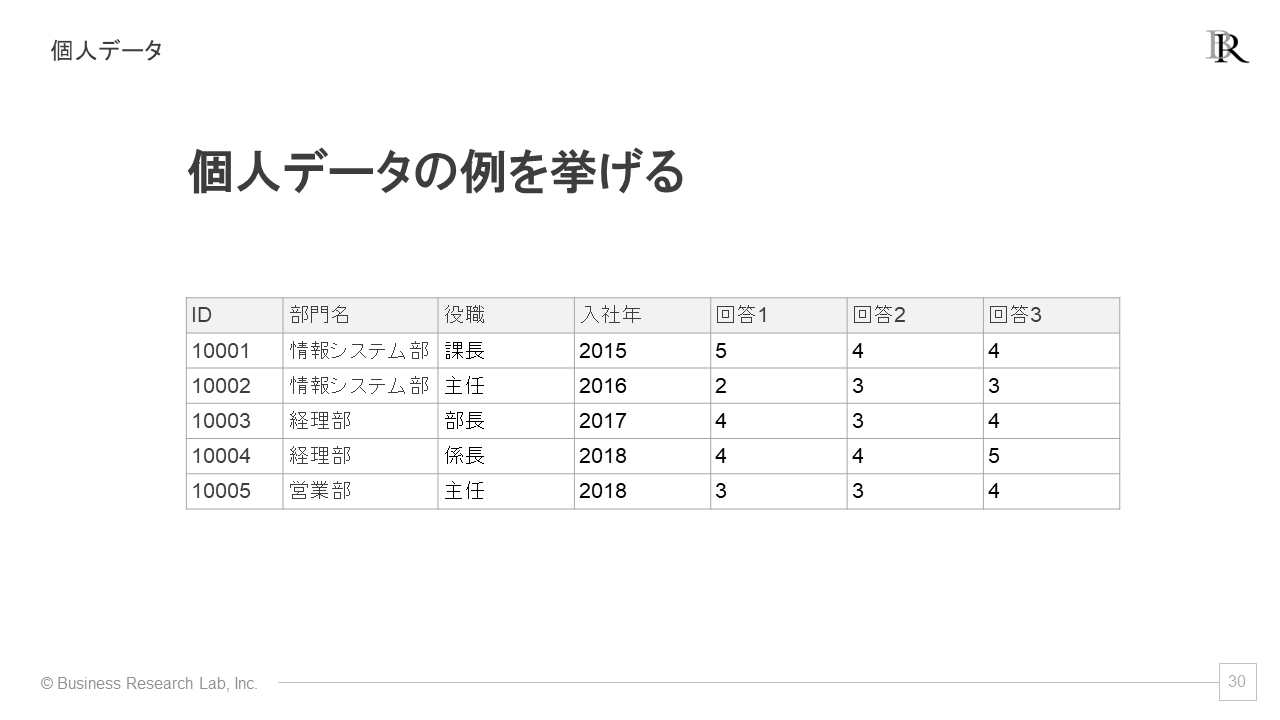
まず、個人データですが、これは個々人の情報が整理されたデータを指します。行が個人に相当するデータになります。例えば、各行に個々人の回答や属性が記録されています。
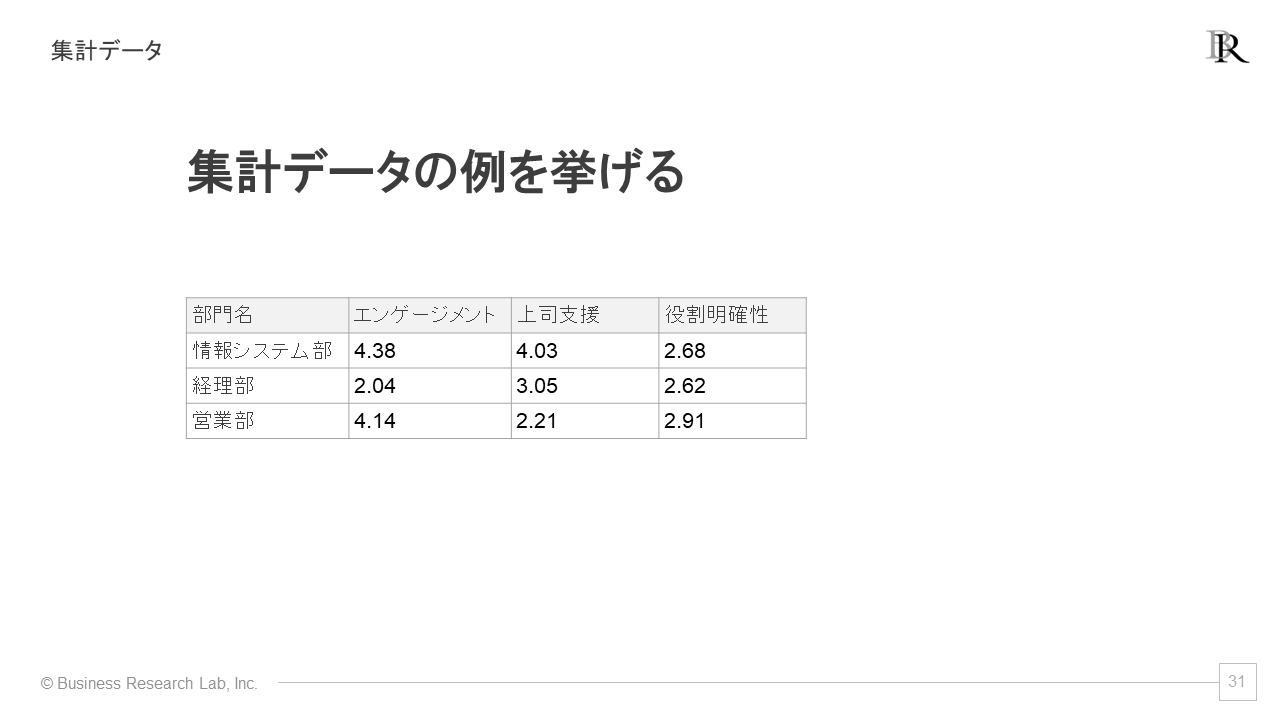
次に、集計データですが、個人データの情報を集約したものです。例えば、部署が行になり、エンゲージメントスコアや上司支援の平均値などが集計されています。
近年、人的資本の開示項目に関するデータが話題になっています。これは集計データの一例です。全社のエンゲージメントスコアなどがそれに該当します。
個人データと集計データには、それぞれのメリットがあります。個人データは、個々人の情報が分かる詳細性が魅力です。
一方、集計データは全体傾向を大まかに把握するのに適しています。例えば、人的資本の開示において、エンゲージメントスコアを提示する場合、個々人のデータをそのまま開示すると複雑ですが、集計データなら概観性が高いと言えます。
基本的には、個人データをもとに集計データを作成することになります。より小さい単位のデータから大きな単位のデータを作るのです。
しかし、このプロセスにおいて、いくつかの重要な情報が失われてしまいます。例えば、個人データから集計データに変換する際に、ばらつきの情報が失われます[1]。
ばらつきとは、個々人の値が平均からどれほど散らばっているかを表します。例えば、組織サーベイにおけるエンゲージメントスコアは人によって異なるでしょう。その違いがばらつきです。集計データになると、通常、この情報が失われます。
他に失われる情報としては、外れ値や異常値です。例えば、エンゲージメントスコアが1点から5点の範囲であるのに、ある個人が10点になっているとしても、見過ごされる可能性があります。
さらに、集計した単位より小さいサブグループの情報も失われます。例えば、部門単位で集計すると、課レベルの情報は失われることになります。
ばらつきの情報、外れ値、サブグループの情報の損失は、分析の幅を狭めることにつながります。特に、ばらつきの情報は分析で重要な役割を果たすことが多く、それが失われることは問題です。
私が伝えたいのは、集計データを作成する際にも、個人データを保持しておくことの重要性です。これは一見当たり前に思えるかもしれませんが、現実には集計データのみが存在し、個人データが保持されていない、あるいはアクセスできないケースがあります。
個人データから集計データを作ることは可能ですが、その逆、集計データから個人データを再構築することはできません。例えば、情報システム部のエンゲージメントスコアが平均6.8点という集計データから、個々人のスコアを特定することはできません[2]。
個人データが残っていれば、このような問題は発生しません。しかし、集計データのみの場合、データの分析可能性が大きく制限されます。
人的資本の開示に際して集計データを開示する際も、集計データの元となった個人データを整然データの形式で保管しておきたいところです。これにより、詳細な分析が可能になり、データの価値を最大限に活用することができます。
集計データのみを基に意思決定を行うとリスクが伴います。営業部と開発部のエンゲージメントスコアの集計結果を見て、営業部のスコアが開発部より低いと判明したとしましょう。
しかし、実は、この情報だけで、開発部が良くないのかどうかを判断するのは待った方が賢明です。統計的に有意な差があるかどうかが、集計データだけではわからないからです。
また、集計された単位での結果を個人に適用してしまうことには注意が必要です。例えば、情報システム部門のエンゲージメントスコアが低い場合も、部門に所属する全員のスコアが低いわけではありません。人によってばらつきがあります。
例を見てみましょう。エンゲージメントスコアが低い部門があるとします。平均は3.2で、この部門には高いスコアを持つ人もいるかもしれません。
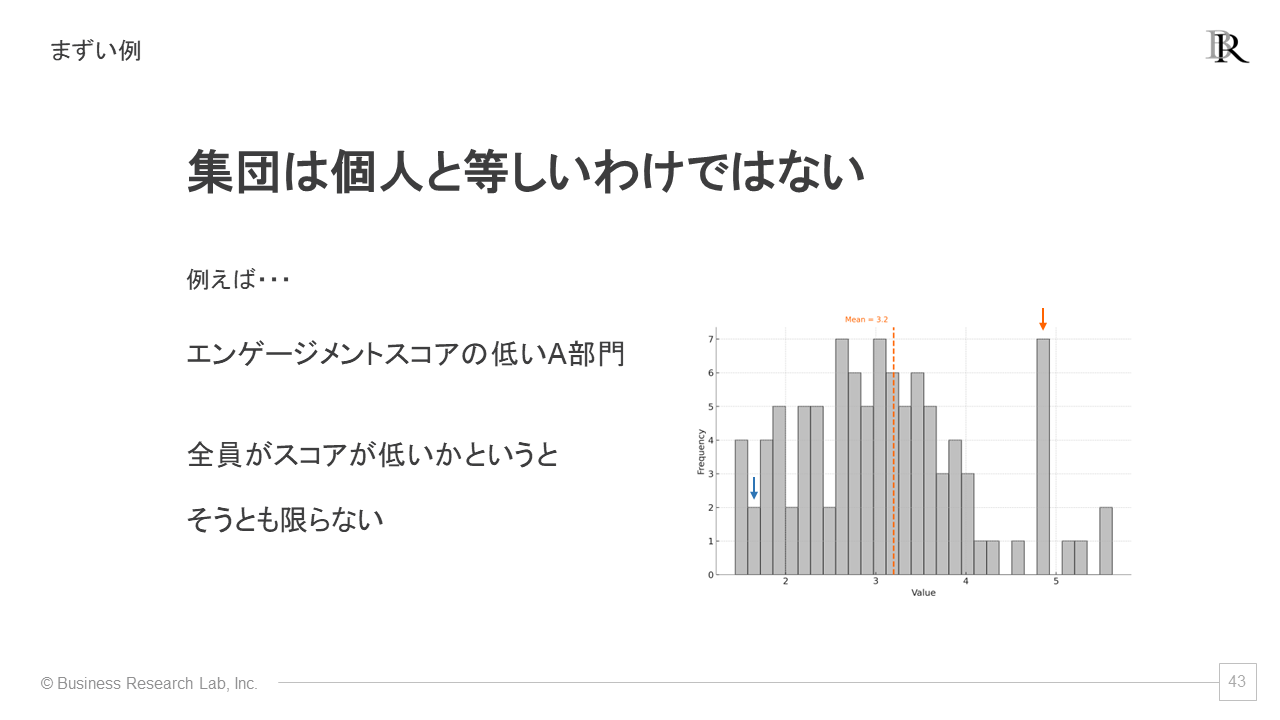 このように、集計データから集団の傾向を把握することは可能ですが、それを個々人に適用することはリスキーです。
このように、集計データから集団の傾向を把握することは可能ですが、それを個々人に適用することはリスキーです。
解釈の際に有用な情報
データ分析を行った後、その結果をどのように解釈し、自社にとって必要な対策をどう決定するかが重要になります。この一連のプロセスのために残しておくと良い情報があります。
まず、教示文です。これは組織サーベイなどで、質問にどう答えるべきかを説明する文章です。例えば、「あなたが仕事に対して感じていることについてお尋ねします。以下の内容があなたの実感にどの程度当てはまるか、お答えください」といったものです。
教示文をデータと一緒に保存しておくことで、質問が何について尋ねていたのかを明確に理解できます。
次に、選択肢も保存しておきましょう。例えば、「全くそう思わない」「あまりそう思わない」「どちらともいえない」「ややそう思う」「非常にそう思う」といったものが選択肢です。
また、対応表の作成と保存も忘れずに行ってください。対応表は、割り当てた数値が何を意味しているのかを整理した表です。対応表がないと、データの意味を正確に理解することが難しくなります。
教示文、選択肢、対応表を残しておくことで、分析結果の解釈が容易になり、誤った解釈の可能性も低減できます。これにより、人事上の意思決定の質を高めることができます。
大きな会社や長期にわたるプロジェクトの場合、教示文や選択肢が年によって変わることがあります。データセットごとに教示文、選択肢、対応表を残すようにしてください。時間をかけて蓄積されたデータの価値を最大限に活用できます。
Q&A
Q:エンゲージメントの分析をしているのですが、集計データしかなく、個人データがありません。この状況で有効な手法や報告のポイントはありますか?
難しい状況ですね。しかし、いくつかの方法が考えられます。例えば、集計データの中でも最も小さい単位のデータを用いて分析を進めるという方法です。
集計データでも単位間のばらつきはあるため、その情報を用いて分析することができます。すなわち、小さな単位の集計データについて整然データを作成します。
もし、この説明だけでは不明瞭な点がある場合、あるいは、より深い理解を得たい場合は、当社に直接お問い合わせいただければと思います。
Q:先日、営業部門にデータ抽出を依頼した際、整然データではないデータが作成されていたため、頭を抱えました。他部門のデータリテラシーを向上させるために、人事部としてできることはありますか?
データリテラシーの向上は重要です。分析しやすいデータと人間が読みやすいデータは必ずしも一致しないというのが、厄介な点です。例えば、セルの結合などは読みやすいのですが、分析を阻害する要因になります。
このような直感に反するデータ整備の重要性を理解し、適切な処理を行うためには、知識が必要です。人事部としてできることは、社内でのセミナーや研修などを通じて知識を提供することでしょう。
知識を得れば、適切なデータ管理は可能になります。他にも、チェックリストなどの具体的なツールを提供し、部門間のデータリテラシーを高めることが、人事部の重要な役割となります。
Q:データ整備を行う際、どのような専門性を持った人に協力を求めると良いですか?
データの整備には、分析の専門知識を持つ人が適しています。データ分析の経験者ならば、本日私が説明した内容を理解し、適切に対応できるはずです。
その一方で、データを実際に分析して、対策を考える際にはドメイン知識も必要です。例えば、採用データの分析では、採用に関する知識が求められます。
さて、これですべてのご質問に回答しました。本日はデータの基礎の基礎についてお話しました。ご質問でもいただいた通り、データ分析の業務でときおり遭遇する例を紹介しました。本日の内容を社内で共有していただくことで、人事データのより良い活用が進むことを願っています。
脚注
[1] ただし、少し複雑になるかもしれませんが、集計データにおいて、ばらつきの情報が得られないわけではありません。例えば、部門単位で集計した際、部門間のばらつきは分かります。それにもかかわらず、個々人のばらつきは、やはり情報としては得られません。
[2] 組織サーベイを行う際には、業者との契約内容を見て、集計データだけでなく個人データも得られるようになっているかを確認しましょう。
登壇者
 伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
神戸大学大学院経営学研究科 博士前期課程修了。修士(経営学)。2009年にLLPビジネスリサーチラボ、2011年に株式会社ビジネスリサーチラボを創業。以降、組織・人事領域を中心に、民間企業を対象にした調査・コンサルティング事業を展開。研究知と実践知の両方を活用した「アカデミックリサーチ」をコンセプトに、組織サーベイや人事データ分析のサービスを提供している。著書に『60分でわかる!心理的安全性 超入門』(技術評論社)や『現場でよくある課題への処方箋 人と組織の行動科学』(すばる舎)、『越境学習入門 組織を強くする「冒険人材」の育て方』(共著;日本能率協会マネジメントセンター)などがある。2022年に「日本の人事部 HRアワード2022」書籍部門 最優秀賞を受賞。




{kind=link}