

2022年12月29日
組織サーベイにおける精度の高い測定の考え方と実践
株式会社ビジネスリサーチラボ フェローの能渡真澄が、組織サーベイにおける測定の問題について講演を行いました。この度、その際の内容をもとに、レポートを作成しました。「組織サーベイにおいて測定したいものをどのように精度高く測定すれば良いか」を学ぶことのできるレポートです。

ビジネスリサーチラボの能渡と申します。本日は、3つの内容について解説します。今回の内容は組織サーベイを意識してまとめていますが、研究における様々なポイントをまとめ直したものです。
- まず、組織サーベイにおいて、質問項目が備えるべき特徴をお話します。測定の妥当性や信頼性、公平性といった枠組みを紹介します。
- 次に、サーベイ実施前の検証事項について述べます。組織サーベイの成否や意義を大きく左右するのは、このフェーズです。
- 最後に、サーベイ実施後の検証事項について説明します。確認的因子分析と信頼性を中心に解説を行います。統計学的な検証の方法をお伝えします。
1.質問項目が備えるべき特徴とは
(1)定義と質問内容を確認する
組織サーベイには、何らかの動機が存在します。例えば、「従業員の状態を把握したい」「成果を高める打ち手を考えたい」といった動機です。
それらの問いに対するひとつの答えを知るために、アンケートを構成します。アンケートによってデータを集めて分析することで、何らかの答えを見出そうとします。例えば、データ分析の結果として、次のような図を示したとします。
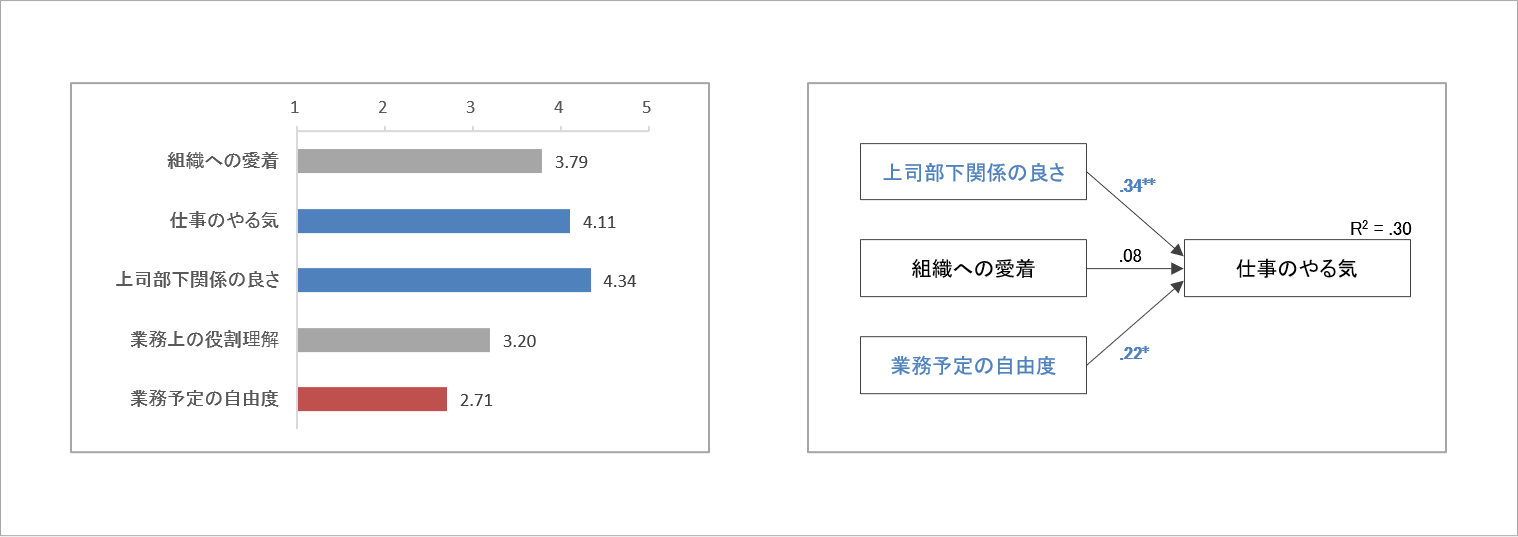
この結果をもとに、「仕事のやる気と関連したのは、組織への愛着と業務予定の自由度だった」「業務予定の自由度の得点は、理論的中点(3:どちらともいえない)を有意に下回っていた」などと述べることができそうです。
しかし、ここで踏みとどまって考えていただきたいことがあります。それは、「分析で取り上げられた各指標は、それぞれどのような概念・事柄を捉えたものか」という点です。
確かに、各指標にそれらしい名前(ラベル)がついています。しかし、図と名前だけであれば、どのような定義かはわかりませんし、どのような質問内容で測定されたのかもわかりません。各指標のデータがその名前と同じ概念・事柄を捉えている保証はありません。
分析結果で取り上げられた、各指標の定義や質問内容を確認する習慣をつけましょう。自分が理解した指標の内容が、実際に測定された内容と異なる可能性があるからです。
組織への愛着を例に挙げると、「愛着」とは何を指しているのか、「組織」の範囲はどのレベルを想定しているか、それらを捉える上で、感情、認識、行動のどの次元まで取り上げるのかなど、捉え方は多様にあります。
「データ上の名前と測定内容がずれる」という問題は、意外と頻発します[1]。それどころか、測定した概念や事柄についてはっきりと定義されていないこともあります。測定されたデータの質を議論する土台が存在しないため、データの内容が適切か判断できません。
組織サーベイにおける分析結果の意義を高め、その後の議論を深めるには、データの測定において「何を捉えたいと考え、どのような内容を、どのような方法で測定したか」を仕上げることが重要です。
(2)妥当性・信頼性・公平性
良い質問項目の特徴について示しましょう。それは、測定の妥当性・信頼性・公平性が示されていることです(AERA et al., 2014)。
- 妥当性:測定したい事柄や概念を正確に捉えられている程度を指します。質問内容や測定したデータの特徴から、質的・量的に検証するものです。
- 信頼性:測定したい事柄や概念を一貫して捉えられている程度を指します。測定したデータを量的に検証して判断します。
- 公平性:測定したい事柄や概念とは関係しない回答者の特徴によって、回答が左右されない程度を指します。数年前から重視されるようになりました。質問内容や測定したデータの分析によって、質的・量的に検証していきます。
質問項目が妥当性・信頼性・公平性を備えるためには、組織サーベイを実施する「前」と「後」で、それぞれやるべきことがあります。ここで重要なのは、「調査でデータを測定する『前』段階に考えるべきことがたくさんある」ということでしょう。
サーベイ実施前の検証事項
組織サーベイの実施前にすべきことを解説していきます。既述の通り、組織サーベイの成否や意義を左右するのは、データを測定した後の分析より、「データを測定する前に、どれだけ測定する事柄や概念を精査して、それを質問内容に反映できたか」です。
(1)定義を検討する
最初に、測定したい概念や事柄を整理し、その定義を設定します。「現実場面の何を捉えたいのか」「何にアプローチしたいのか」といった問題意識を土台に、測定したい事柄や概念を整理し、それらの定義を行いましょう。
このプロセスでは、どの概念や事柄を取り上げるかという選択があります。取り上げる概念や事柄に困ることがあるかもしれません。そのようなときは、現実場面・現象に関わる人のコメントや意見を探ったり、先行研究における取り上げ方を参照したりしましょう。
前者については、予備調査で自由記述やインタビューなど質的データを集める方法があります。それ以外に、それに関する非専門家向けの書籍を読んでみたり、SNSなどにある意見を眺めるなどして、自分にはなかった観点や発想を膨らませていく方法も考えられます。
組織サーベイで捉えたい概念・事柄が定まったら、次にそれらの定義を設定していきます。組織サーベイで取り上げる事柄や概念は、具体的にどういったものかを決めていく作業です。
なぜ定義が必要なのでしょうか。定義がされていない事柄や概念は、それが何であるか個人で解釈が分かれ、何を捉えたものか定まりません。加えて、定義がないと、何を重視して測定に用いる質問項目を作ればよいかがわからず、作成した質問項目が適切かどうかも評価できません。
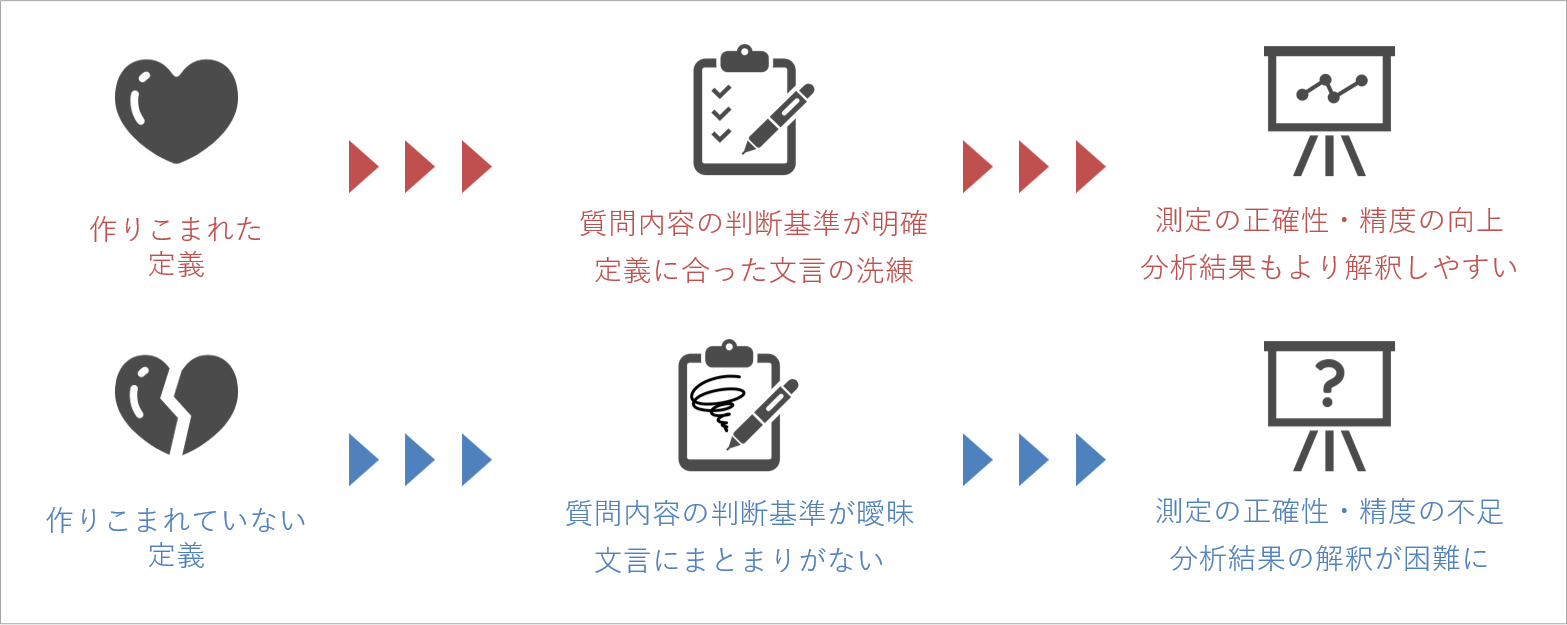
もちろん、定義を設定するにしても、その中身がしっかりしていなければ、結局、同じ問題が起きます。
定義が作りこまれた概念や事柄は、質問を作成する際の基準が明確です。質問項目が作りやすく、作成した内容が適切か判断しやすいため、洗練することも容易です。そのように作成された質問項目は、データ測定の正確性や精度が高まり、分析結果も解釈しやすくなります。
一方、定義が作りこまれていないと、質問を作成する際の基準が曖昧になります。どのような質問項目を作ればよいかわからず、作成したものが適切かの判断も難しくなります。その結果、データ測定の正確性や精度は落ち、分析結果の解釈も難しくなるのです。
概念・事柄を定義する際のコツは、測定したい事柄や概念の内容に何を含め、何を含めないかの境界を考えることです。

例えば、仕事のやる気でいえば、やる気を出して仕事に打ち込んでいる「行動」として捉えることも、仕事に対する熱い想い・情熱といった「感情」として捉えることもできます。ある事柄や概念が持つ様々な側面について、何を含めて何を含めないかを考えます。
「先行研究の定義を引用して終わり」ではなく、その定義が含めていない側面をよく理解し、定義に含めるものと含めないものを定めるに至った理論的背景も把握・整理しましょう。
定義を考える中で、様々な側面を包括的に取り上げ、一つの概念として捉えたい場合もあるはずです。仕事のやる気の定義として、仕事に打ち込む行動的な側面と、仕事に対する情熱といった感情的な側面のどちらも含めたい場合です。
そのようなときに意識したいポイントは、「定義で取り上げたすべての側面が相関するか考える」ことです。例えば、部下が回答する上司部下関係の良さを、様々な側面から包括的に捉えることを考えたとします。

上司部下関係の良さを図中の3側面で捉えようとした際、それらの側面が相関するか、つまり、上司からの支援が多いと回答する人は、上司と自分が互いに信頼している感覚も、プライベートの交友頻度も高いと回答しそうかを考えてみます。
これらとよく似た概念を取り上げたメタ分析や複数の先行研究で示された相関関係を見ると良いでしょう。あるいは、これは妥協策ですが、測定したい概念をめぐる現実場面を想像し、相関がなさそうな状態を考えてみるといった方法もあります。
上司部下関係の良さを想像してみると、上司からの支援の多さと互いに信頼している感覚は十分に強い相関があると推測できます。上司からの支援が多いと答える人は、上司と自分が互いに信頼している感覚も高いと答えそうであり、そうならない状況はあまり思いつきません。
一方、上司からの支援の多さや互いに信頼している感覚と、プライベートの交友頻度は、相関しない場合が考えられます。上司からの支援が多かったり、互いに信頼していたりする間柄でも、プライベートで接点がないことは想定できます。
プライベートの交友頻度は、支援の多さや互いの信頼感とは異なる次元の事柄や概念によって回答が違ってくる側面だと思われます。プライベートの交友頻度を除いたほうが概念全体のまとまりが良くなるため、定義に含めないという判断をすることもできます。
そうは言っても、「今回の組織サーベイにおいては、プライベートの交友の側面を捉える積極的な理由がある」など、これを除きたくない場合も考えられます。
そのときは、上司部下関係が持つ複数の特徴を、ひとつの概念の項目として混ぜこまないほうが良いでしょう。それらの特徴は、上司部下関係の良さという大きな概念を構成する下位概念の一つとして捉え、下位概念それぞれに対して複数の質問項目を作成するのがベターです。

こうした試行錯誤を繰り返して、自分の捉えたい概念や事柄の捉え方を整理し、定義を洗練していきます。
(2)仮説を作る
組織サーベイにおいて測定する各指標の定義を決めたら、それらの指標を用いて仮説を作っていきます。仮説とは、これから測定されるデータに関して予測される、指標間の関連性や得点の状態を述べたものを指すことにします。簡単に言えば、測定後のデータ分析で示されるであろう結果の予測です。
仮説を考える上で必要なのは、各指標を成果指標と影響指標に分けて整理することです。組織サーベイで測定する各指標について、どれが結果(成果指標)にあたり、どれが原因(影響指標)にあたるのかを事前に定めます。

なぜ仮説が必要なのかというと、組織サーベイにおいて、何を成果・結果としており、何をそれらの原因・要因として取り上げたかを明確にするためです。これは、ぶれてはいけない枠組みです。
質問項目を作る
捉えたい事柄や概念の定義と、各指標を取り上げた仮説が設計できたら、ようやく、定義に応じた質問内容を作成していくことになります。ここで、質問項目を作成する際に意識していただきたい点を2つ紹介します。
まず、質問項目は1概念につき、最低でも3項目以上を準備することを勧めます[1]。これは、各指標の定義内容をできるだけ広く捉えることにつながります。また、項目が多いと、得点のバリエーションが増えて各回答者の特徴をよりきめ細かく得点に反映できると考えられるからです。
次に、逆転項目は無理に作らなくてよい、というものがあります。逆転項目とは、測定したい概念や事柄とは敢えて逆の特徴を問う質問項目のことです。例えば、上司部下関係の良さにおける「上司から嫌われているように感じる」といった項目は、逆転項目です。
逆転項目は、意図せぬ概念を測定しがちであり、適切な逆転項目を作成するのは至難の業です。敢えて逆転項目を作ろうとせず、測定したい概念をストレートに問うことを私は勧めます[2]。
妥当性と公平性を検証する
以上の2点を踏まえ、各概念の定義をもとに質問項目を作成していき、アンケート全体を作っていきます。しかし、質問項目をまとめ終わっても、すぐに組織サーベイの実施とはいきません。質問項目が出来上がったら、妥当性と公平性を検証する必要があります。
まず検討することは、表面的妥当性と内容的妥当性です。
- 表面的妥当性:個々の質問項目の内容が定義を適切に捉えているかを指します。質問項目一つひとつが、指標の定義に何を含めるのか斜め含めないのかを守った内容になっているかを確認します。
- 内容的妥当性:ある指標に含まれる質問項目全体で、定義された内容を網羅的に捉えているかを指します。指標の定義が含めた側面を質問項目がフォローできているか、項目の内容を見渡して確認します。
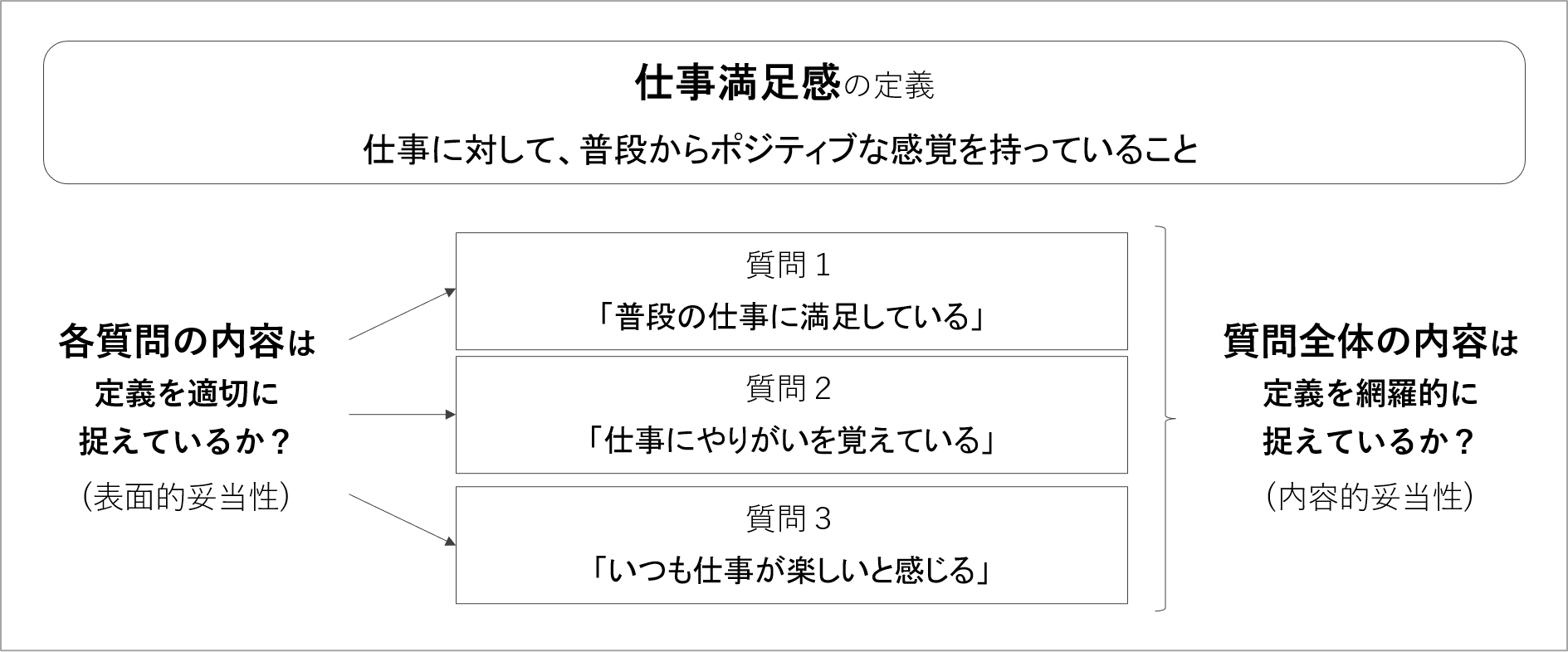
上図の例では、仕事満足感の3項目の妥当性を検証しています。3項目ありますが、それぞれの項目は定義通り、「仕事に対する」「回答時の状態でなく普段の状態に焦点を当てた」「ポジティブな感覚」を質問できているように見えます。ひとまず、表面的妥当性に問題はなさそうです。
ただし、これらの質問で、定義が指す「ポジティブな感覚」全体を包括的に捉えられているかは、議論があるでしょう。この点は、定義におけるポジティブな感情が何を含めるかによって判断が変わるもので、事前に決めた基準に応じて考えていくことになります。
仮に、ポジティブな感覚を「回答者が実感する感覚的な側面に限定し、仕事におけるwell-being[3]の感覚も含めたもの」として、この3項目を考えてみましょう。
その場合、質問1は仕事に満足している感覚そのものです。質問3はいわゆるhedonic well-being、質問2はいわゆるeudaimonic well-beingを捉えたものになります。3項目の制約の中では、この内容で最低限網羅できていると見なせます。
端的に言えば、ここは「作成した質問内容が、指標の定義に合っているか」を確認する段階です。作成した質問内容と定義を照らし合わせて、各々の内容の適切性と網羅性を複数人で確認するのが良いでしょう。
続いて、回答に際して誰もが不当に損をしないよう質問内容を工夫・調整することも重要です。これは、測定の公平性の議論になります。

公平性とは、測定したい概念や事柄に対して、それとは関係しない回答者の属性によって回答が左右されないことを指します。回答者の属性とは、性別や部署、役職、年代といった特徴のことです。
例は、専門用語を並べた質問項目に対して、それに馴染みのない中途採用者が回答する場面を想定しています。この質問項目で「仕事に対する情熱、熱い感情を持っていること」としての「仕事へのやる気」を測定しているとします。
仮に中途採用者が仕事に対するやる気を持っていたとしても、専門用語の知識が十分になければ、この質問に「あてはまる」と回答できないでしょう。このように、測定したい概念や事柄と関係がないところで回答が左右される項目は、公平性が低い項目として修正すべきです。
性別や年齢、役職などによって、回答できなかったり評定が低くなったりするような、不公平な項目がないかを確認するのが、ここで行うべきことです。様々な属性・立場の人が回答に困ったり回答が歪んだりする可能性がないか、調査対象者に近い立場の人も交えて、質問項目全体を確認しましょう。
項目作成時によくあるミス
最後に、質問項目の作成時に、ありがちなミスを2つ紹介します。一つは、測定したい事柄や概念の定義と、それが伴う特徴を混同しているミスです。

先ほど、定義の中に何を含めていないかしっかり考えるべきだと述べました。その理由は、含めていないはずの側面を、意図せず含めることがとても多いからです。
例えば、上図において、組織への愛着を測定する3項目が並んでおり、定義が記されています。定義は「組織を大切に思い、感情的なつながりを感じていること」です。
この定義のみが示されていたら、ここで捉えられている組織への愛着は、「職場やチームでなく、組織に向けたものであり」「感情的なつながりの側面を重視し」「感覚的な側面に絞っている」と理解できます。
それに対して、Q2は「企業理念に共感している程度」を聞いています。これは「感情的なつながりの実感」を捉えるものではありません。確かに、組織に愛着を感じている人には、企業理念に共感している人は多そうです。
しかし、企業理念に共感していることは、組織に愛着を持っている人が備えている特徴であり、組織への愛着そのものを表すものではないのです。組織に感情的つながりを感じることと、組織理念に共感することはイコールではない、ということです。そのため、Q2は内容が少しずれていると考えられます。
また、Q3は「行動している」と、感覚的な側面に絞る定義に対して、行動頻度を問う質問内容になっており、これも測定概念とずれています。このような行動的な側面も一緒に捉えたいなら、定義において「組織との結びつきを確認し、周囲に示すような行動を含む」など、明記すべきです。
この例のように、「定義に含んでいない側面を捉えてしまっている」ケースはよく見ます。質問項目を確認する際には、ぜひ注意していただきたいと思います。
もう一つのありがちなミスは、「1つの質問項目の中で2つ以上の内容を聞いている」というものです。

上図の例では、上司への満足感の質問として、「上司の指導力への満足」と「仕事の速さへの満足」の2側面を、一つの質問の中で聞いています。これはダブルバーレル項目と呼ばれ、避けるべきものです[2]。
なぜなら、問われた複数の特徴のうち、「あてはまるものもあるが、あてはまらないものもある」回答者は、回答に困るからです。例でいえば、上司の指導力に満足はしているが、上司の仕事を速いと思わない人は、回答に困るでしょう。
得点の意味する内容が異なる可能性が高いという問題もあります。「上司の指導力に満足しているが、仕事の速さはほどほど」としてこの質問に「あてはまる」とつけた人と、「上司の指導力には不満があるが、仕事はかなり速いと思う」としてこの質問に「あてはまる」とつけた人では、得点が同じでもその意味合いが異なります。
同じ得点なのに中身が質的に異なると、データ分析が適切に行いづらくなり、また結果の解釈が難しくなります。
質問項目の内容は、一つの内容のみ問う形になるよう意識しましょう。加えて、2つ以上の内容になるのであれば、質問項目を複数に分けて対応します。例えば、「上司の指導力への満足」と「上司の仕事の速さへの満足」の2項目に分けて、それぞれ質問すればよいです。
サーベイ実施後の検証事項
ここからは、調査を実施してデータを取得した後の検証事項を解説します。
(1)因子妥当性の検証
まず、質問項目が想定通りにまとまるかをデータ分析で検証します。質問作成においては、複数の質問項目で一つの概念を測定するよう構成していました。それがうまくいっているかを分析します。
ここで検証される妥当性を「因子妥当性」と呼びます。因子妥当性とは、質問内容が、想定された通りに概念のまとまりを捉えられていると統計学的に判断できるかを指します。
因子妥当性を検証する分析手法を因子分析と呼びます。因子分析には2つの枠組みが存在しますが、ここでは「各質問項目がどの概念を測定するか、対応付けが事前にできている」状況であるため、それを分析する確認的因子分析[4]を紹介します。
確認的因子分析とは、想定した因子モデルに対して、取得したデータがどの程度適合しているかを検証する手法です。加えて、各質問項目への回答データが持つ得点要素が、背後に想定される因子によってどれだけ説明されるかも示すことができます。
因子分析について詳細を説明する前に、質問項目の回答データに関する理論上の前提を示します。各質問項目への回答は、測定したい概念や事柄のみで決まりはせず、他の概念・事柄や偶然の要因によって定まる部分もある、ということです。

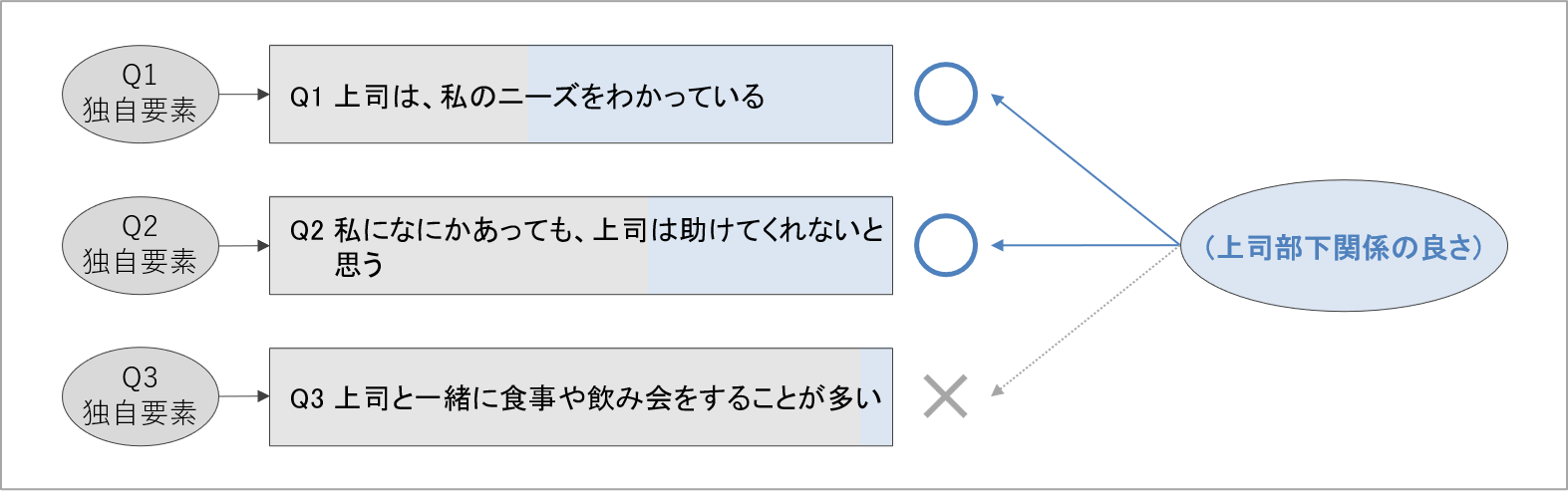
例えば、「部下が報告する、上司と部下が普段から仕事で仲良く付き合っていること」を指し、感情面と行動面の両方を含める概念を「上司部下関係の良さ」と定義したとします。この上司部下関係の良さを測定する項目として、「上司との関係は良好だと思う」という質問を考えてみましょう。
「上司との関係は良好だと思う」への回答は、上司と部下が普段から仕事で仲良く付き合っていると部下が捉えている場合、高くなりそうです。しかし、仮に普段は上司とそこまで仲良くやれていないけれども、組織サーベイに回答した数日間で上司から仕事ぶりを褒められた社員は、回答値が高くなるかもしれません。
これは、普段は仲良くはないと感じている部下が、調査回答時の偶然の機会によって得点が高まっている状況です。測定したい概念や事柄と異なる要因によって、回答が左右されていると考えられます[5]。
このように、質問項目への回答値には、測定したい概念によって得点が定まる要素と、測定したい概念とは関係のない要因で得点が定まる要素が存在しています。
続いて、「上司と一緒に食事や飲み会をすることが多い」といった質問項目を考えてみましょう。確かに、上司と部下が普段から仕事で仲良くやっていると、食事や飲み会でともに過ごす機会も多いかもしれません。
しかし、仕事において上司と仲良くやれている部下でも、上司と食事や飲み会をしない人がいる可能性も十分に考えられます。この質問への回答値は、測定したい概念「普段から上司とどれだけ仲が良いか」の程度に、回答値が対応していない質問と考えられるわけです。
質問項目への回答値が含む「測定したい概念によって得点が定まる要素」の多さは、項目ごとに異なります。因子分析は、「測定したい概念によって定まる要素が、各質問項目にどの程度含まれているか」を検証する分析なのです。
以上を踏まえて、分析で用いる語句を整理しておきます。「測定したい概念や事柄によって定まる得点要素」を生み出すものを共通因子、「測定したい概念や事柄と異なる要因によって定まる得点要素」を各項目に生み出すものを独自因子と呼びます[6]。
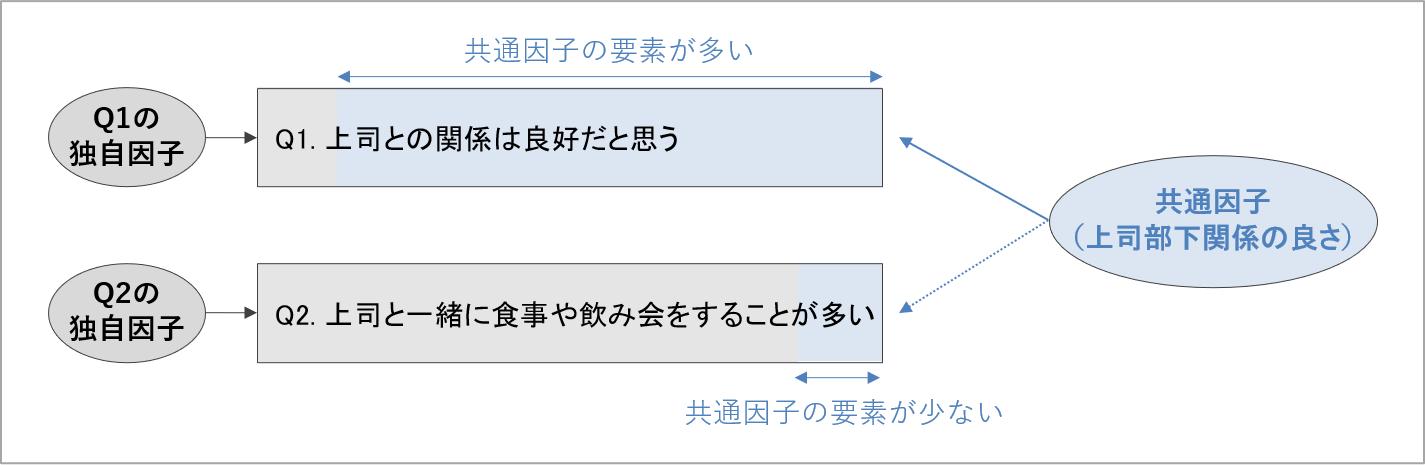
概念や事柄の測定に用いた項目が、共通因子によって大きく影響されて得点が定まっていたとみなせれば、それは共通因子の要素が多い項目です。「測定したい概念によって、項目の得点が上下している」と判断できます。
他方、共通因子によって得点がほとんど影響されないとみなせる項目は、共通因子の要素が少ない、つまり「測定したい概念とは関係ない要素によって得点が上下している」と判断できます。
複数作成した質問項目のうち、共通因子からの影響が小さかった項目は削除すべきと考えられます。共通因子からの影響がどのくらいあるかを表す指標は、「因子負荷量」と呼ばれます。因子負荷量は、-1~+1の範囲で示される指標で、数値の絶対値が1に近いほど共通因子による回答値への影響が大きいことを表します。
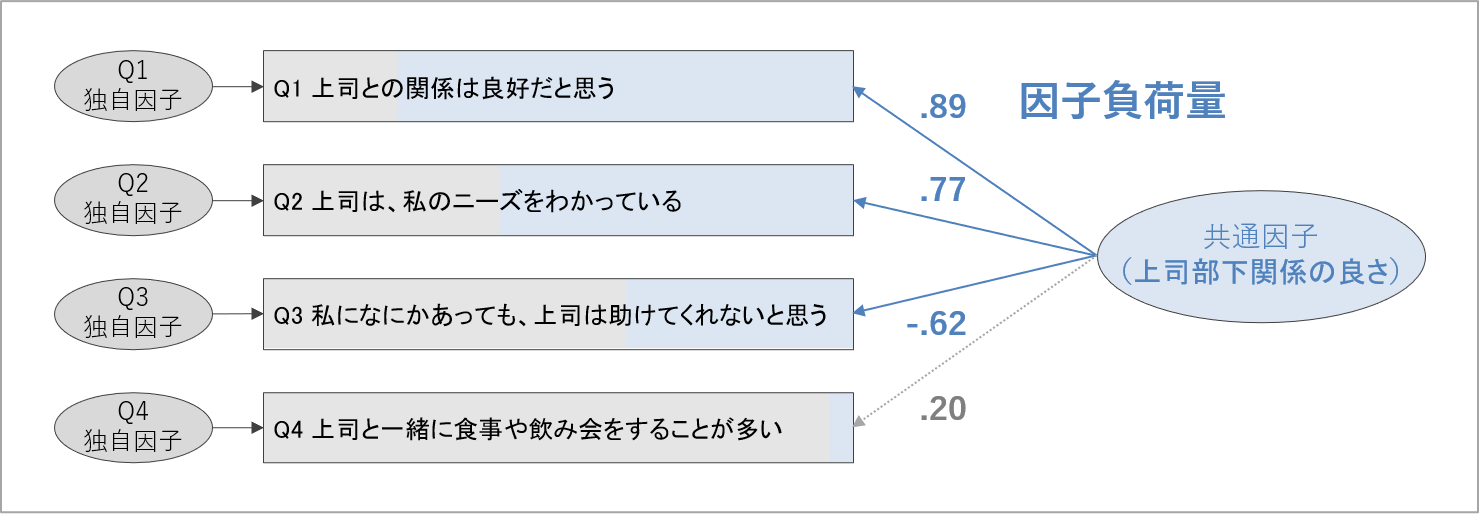
因子負荷量が+(プラス)の項目は、共通因子の程度が高いほど項目の回答値が高くなることを表します。逆に、因子負荷量が-(マイナス)の項目は、共通因子の程度が高いほど項目の回答値が低くなることを表します。
因子負荷量が小さい項目は、共通因子によって得点が左右されないと見なされるわけですが、因子負荷量はいくつあれば大きい/小さいと判断されるのでしょうか。
これは様々な基準が提案されています。その中でも、心理尺度構成の手続きをまとめた研究では、因子負荷量の絶対値が.40以上ある項目は、共通因子によって得点が十分に定められていると判断して良いとしています(Devon et al., 2007)。今回は、この基準で共通因子によって得点が定められる項目とそうでない項目を見分けていきます。
さて、因子分析の細かな検証事項を先にお伝えしましたが、確認的因子分析では、先に検討しなければならないことがあります。それは、「測定したい概念や事柄が一つの共通因子の影響で得点が左右される」想定が、そもそもデータに合っているかです。
これを検証する指標として、「モデル適合度」と呼ばれるものがあります。モデル適合度の値が全体的に見て問題ない範疇にあるとき、「作成した項目が、測定したい概念や事柄を表す共通因子一つだけに影響される」という因子モデルは、調査で取得したデータによく当てはまっているとみなせます。
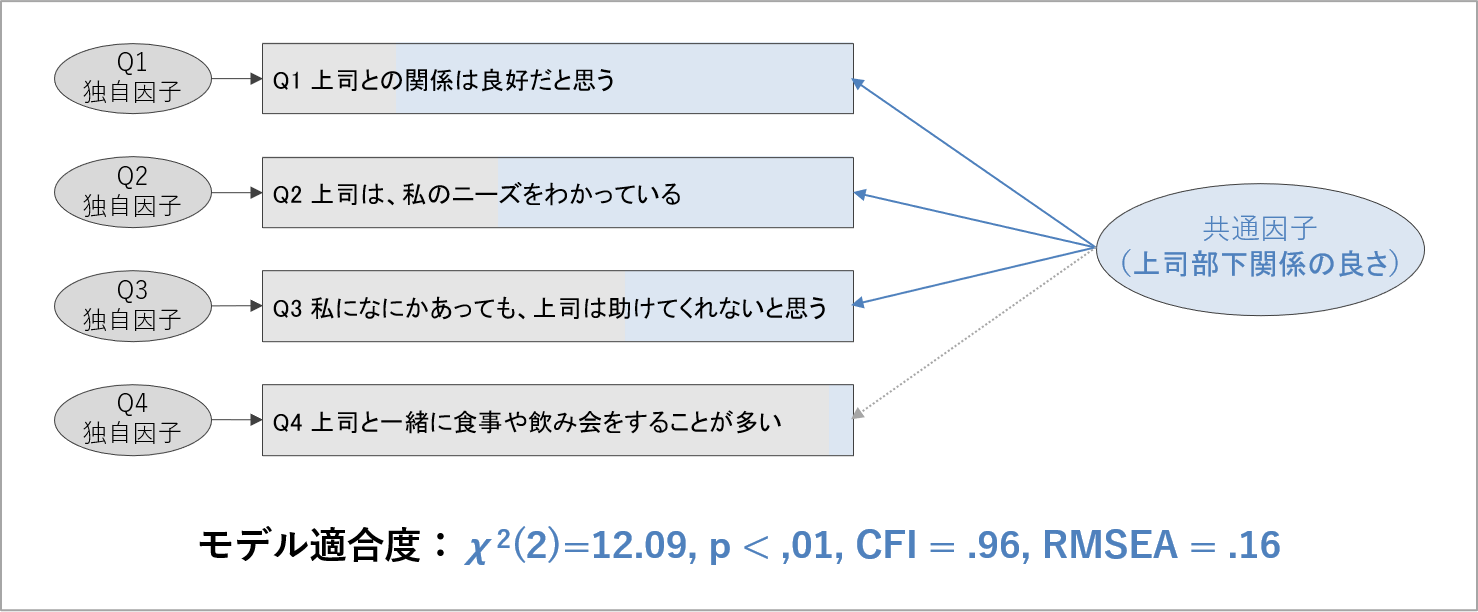
モデル適合度の基準を示しておきましょう。モデル適合度には様々な指標が提案されていますが、その中でも心理学の研究でよく用いられるものをピックアップします。判断基準の値は領域間で異なることもあります[7]。

モデル適合度を見る上での注意点ですが、1つの概念に対して質問項目の個数が3個以下だと、モデル適合度による検証はできなくなります。
質問項目数が3個で1つの共通因子を推定する因子モデルは「飽和モデル」と呼ばれ、モデル適合度が必ず最良の値になります。質問項目数が2個以下だと、モデル適合度の計算ができません。
したがって、質問項目数が3個以下だと、モデル適合度を見る意味がなくなります。こうした事情も加味しつつ、1つの概念につき、多くの項目を作成しておくのが良いでしょう。
追加の注意点として、因子分析を適切に行うには十分なサンプルサイズが必要です。ある統計学の教科書(Hair et al., 2014)では、最低でも100名、あるいは、一つの因子分析に含める質問項目の個数の10倍の人数を確保することが推奨されています。
個人的なさじ加減としては、ひとまず200名から300名、少なくとも150名強は回答者を集めることをお勧めしたいと思います。経験上、これより少ない人数では、分析結果があまり安定しません。もちろん、300名を限度とせず、様々なタイプの回答者を数多く集められるならば、それに越したことはありません。
それでは、因子分析を実施する流れを見ていきましょう。上司部下関係の良さの項目として5項目作成した例を出しています。なお、因子負荷量の正負の意味を説明するため、敢えて逆転項目をQ3に設けています。ここで示す分析結果は架空の数値例です。因子分析の展開だけ追っていただければと思います。
最初に、分析ツールを用いて先ほど示したような因子モデルを描き出します。AmosやHADなど、ツールによっては、図を実際に描くこともあります。あるいはRのlavaanパッケージでは、プログラム言語でモデルを記述することもできます。
因子モデルを描いたら、ツールに従って分析を実行します。細かなセッティングもありますが、ひとまずデフォルトの設定で良いでしょう。多くの場合、最尤法で分析が実行されます。
分析を実行したら、最初にモデル適合度を確認します。この指標が悪い値だと、「測定した各項目の得点が1つの共通因子によって定められるモデル想定は、データに当てはまっていない」となり、因子モデルを考え直さなければなりません。

上記の例では、モデル適合度は基準を満たす良好な値であり、「5つの項目が一つの共通因子によって説明される因子モデルは、取得したデータによく当てはまっている」と見なせます。5つの項目が一つの概念でまとまる想定をすることに、ひとまず問題ないと判断できるわけです。
続けて、各項目の得点が共通因子によってどのくらい影響されているかを、因子負荷量を見てみます。因子負荷量の基準である絶対値が.40を超えるか否かで、評価してみましょう。
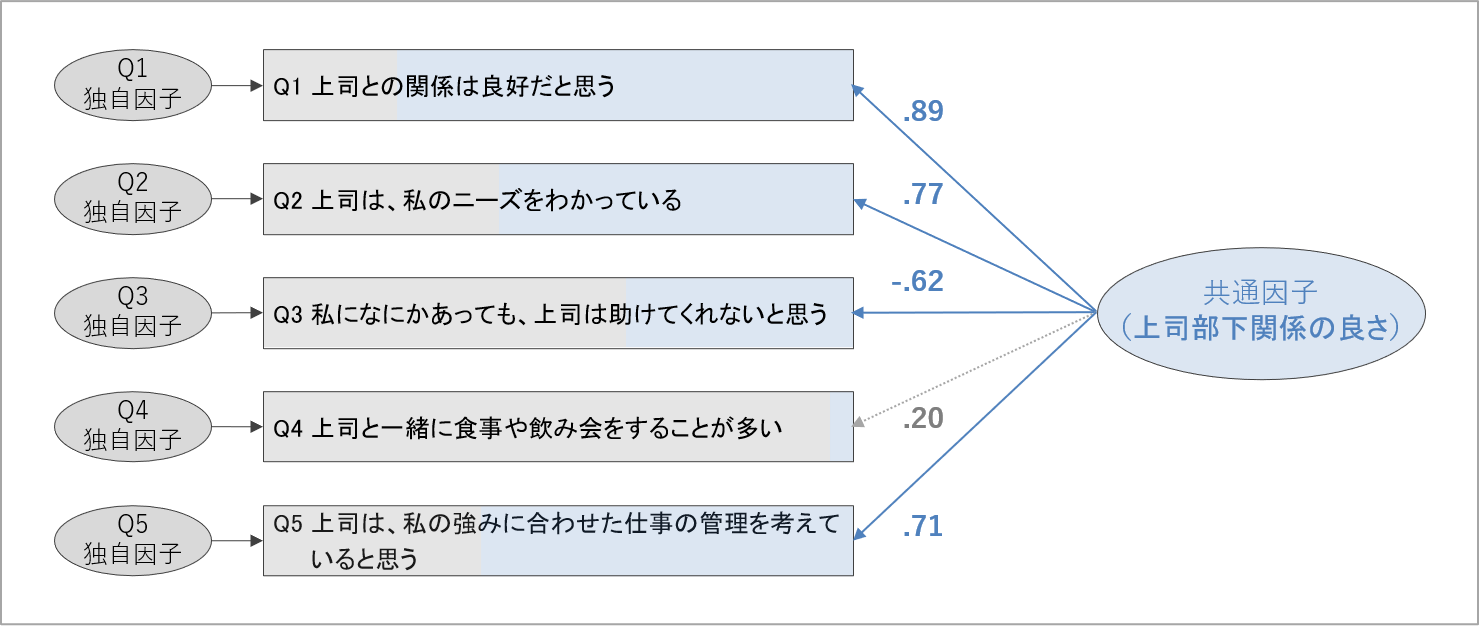
Q4の質問項目のみ因子負荷量が.20と小さく、他の項目は因子負荷量の絶対値が.40を超えています。Q4の質問は共通因子によって得点が左右されず、独自の要因によって得点が左右されていると見なせます。
したがって、Q4は「測定したい概念の程度を捉える質問項目として、うまく機能していない」と判断できます。ここでは、この項目を敢えて用いなければならない理論的な必然性・有用性は小さいと判断できたとして、上司部下関係の良さを測定する質問項目から除外します。
なお、Q3だけ因子負荷量がマイナスの値になっています。これは、「共通因子の程度が高いほど、Q3の回答値が小さくなっていく」ことを表しています。Q3の質問内容を見ると、これは逆転項目であり、得点が高いほど測定したい概念の程度が低いことを表しています。
Q3に対して因子負荷量がマイナスになるのは、想定通りの結果です。この例のように、逆転項目を含めた因子分析では、項目作成がうまくいっている場合、逆転項目とそうでない項目の因子負荷量は正負が逆になります[8]。
最後に、因子負荷量が小さい項目を除外した4項目で再度因子分析を実行し、最終的な分析モデルの結果を確かめます。先ほどと同様の分析手続きを、Q4を除いて実施するだけです。
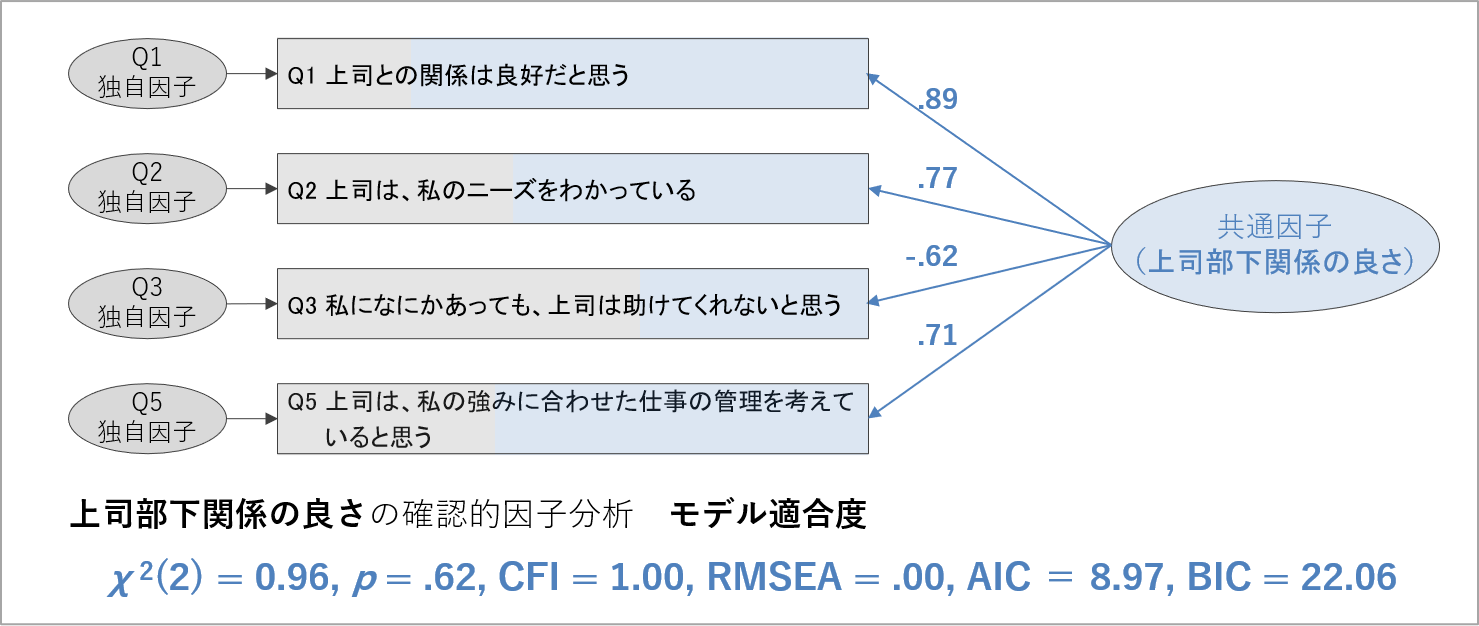
Q4を除いて分析すると、最初の分析モデルと比べて、モデル適合度はさらに良くなっています。BICとAICの値がより小さくなり、取得したデータにより当てはまるモデルであることが示されています。
すべての質問項目の因子負荷量も十分な大きさとなり、これら4項目の得点が一つの共通因子によって定められていると見なせます。ここに至って、ようやく測定したい概念を捉える項目の洗練を終えたことになります。
ちなみに、確認的因子分析を用いた有用な分析テクニックもあるため、合わせて紹介しておきます。それは「測定した質問項目が、どういった概念のまとまりで分けるとよいか、様々な可能性を比較検証できる」ことです。

例えば、上司の助言に関する質問項目を作成する場面を考えてみます。担当者は、問題解決に向けた具体的なアドバイスを部下が受け取っていることを表す「問題解決的な助言」と、部下のメンタルケアに配慮したアドバイスを部下が受け取っていることを表す「心理支援的な助言」の質問項目を、それぞれ3項目ずつ作成しました。
この観点は、「上司からの助言6項目は、2つの共通因子がそれぞれ3項目ずつの得点に影響する構成を持つ」という因子モデルに該当します。
それに対して、社内で「上司からの助言は、そのように細分化せず、全体的に助言を受け取っていることが重要なのでは」と疑問が出たとしましょう。この観点は、「上司からの助言6項目は、1つの共通因子で捉えるのが良い」という因子モデルに該当します。
作成した6項目に対して、2因子に分けて捉えるモデルが良いのか、1因子でまとめて捉えるモデルが良いのかを判断する必要が出てきました。このようなとき、確認的因子分析のモデル適合度を用いた比較が活用できます。
それぞれの因子モデルを想定した確認的因子分析を行えば、各因子モデルでモデル適合度や因子負荷量が示されます。それらを因子モデル間で比較し、どちらの因子モデルがよりデータに当てはまっているかを統計学的に検証すればよいのです。
6項目の得点が一つの共通因子に影響されるモデルで確認的因子分析を行った結果が、以下のものです。数値は架空例なので、分析の展開だけ追ってください。
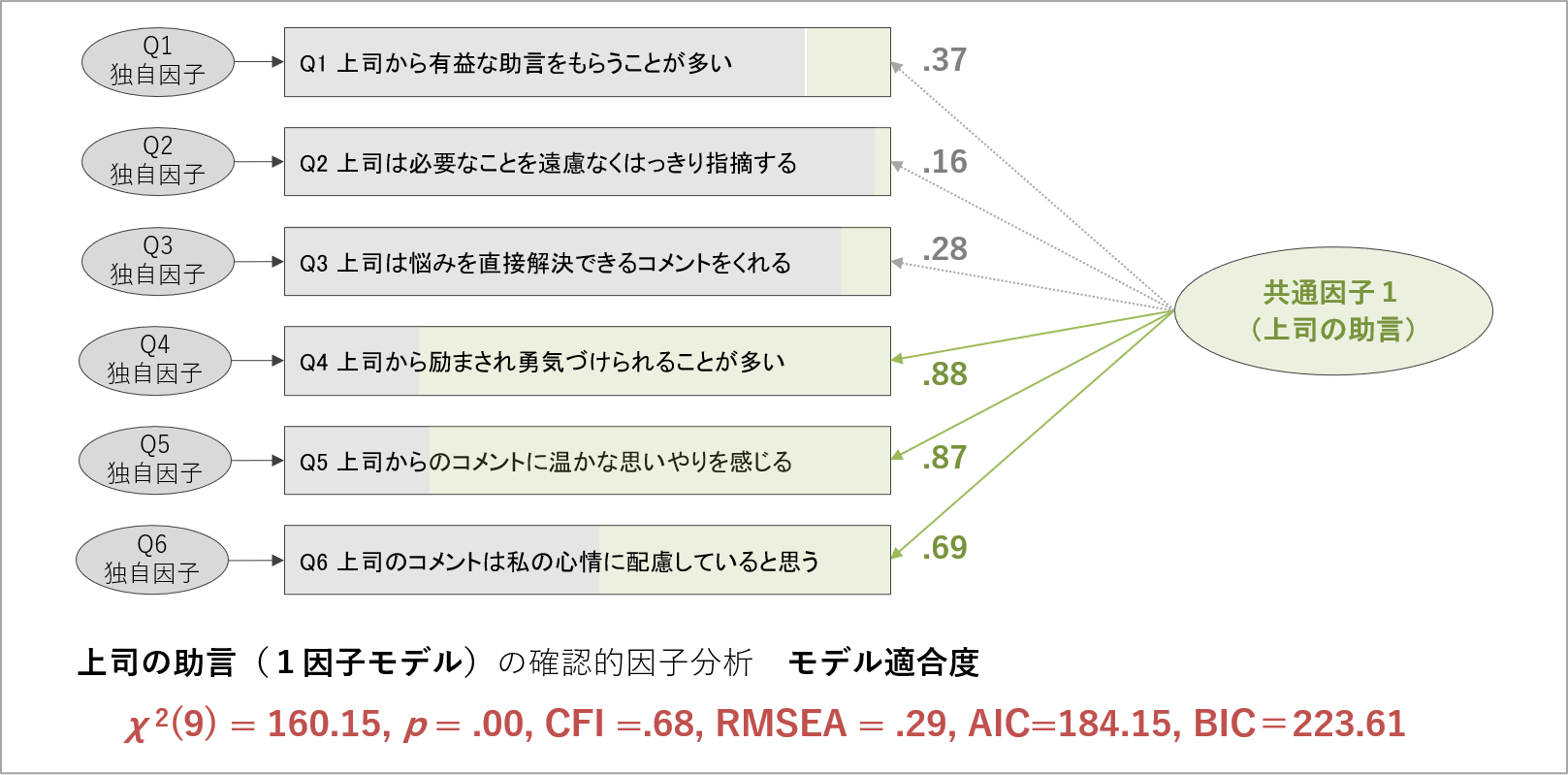
6項目を1因子でまとめた因子モデルのモデル適合度は、すべての指標が基準を下回り、取得したデータにうまく当てはまっていません。各項目の因子負荷量も.40を下回る項目が複数あります。
他方、6項目の得点が2つの共通因子に影響されるモデルで確認的因子分析を行った結果が、以下のものです。2因子で捉えた因子モデルのモデル適合度は、すべての指標が基準を満たしており、取得したデータに当てはまっています。各項目の因子負荷量も十分に高く、各項目の得点が対応する共通因子に定められていることが示されています。

2つの分析結果を見ると、2因子に分けて捉えた因子モデルの方が、モデル適合度はもちろん、因子負荷量の面においても、良いモデルだと分かります。この結果により、上司の助言を測定したこの6項目は、1つの概念でまとめて扱うよりも、2つの概念に分けて捉える方が適切だと主張できるわけです。
このように、確認的因子分析を駆使すれば、因子モデルの様々な可能性を分析で比較することが可能となります[9]。
(2)信頼性の検証
因子分析を終えたら、次は各指標の得点に十分な一貫性があるか検証を行います。ここで検証する得点の一貫性のことを「信頼性」と呼びます。
因子分析では、各質問項目の得点が測定したい概念や事柄の程度によって定められるか、因子負荷量に基づいて個別に検証していました。対して、ここでは「各質問項目の回答値を平均・合計して指標の得点を算出する際に、その得点全体が概念をうまく反映しているか」を検証しています。
なぜ得点の一貫性が問題になるのかを、直感的なイメージで説明したいと思います。例として、ある企業の新卒採用において、4名ずつ2組の採用チームがあったとしましょう。各チームで候補者の面接を行い、4名がそれぞれ候補者を0~5点で評価し、その平均を面接評価点にすると決めています。

加えて、チームの4名は評価シートを用いるなどして評価基準を共有し、同じ基準で候補者を評価しているとします。その状況で、採用チーム1と2の評価データが上図のようになっていました。チーム全員が、同じ評価基準で得点を考えていることがポイントです。
この得点を見て、あなたはどちらのチームがより適切に候補者を評価できていると感じますか。わかりやすくするため、4点以上は赤色、2点以下は青色で塗っています。
採用チーム1は、候補者に対する4名の評価がおおよそ一貫しています。Aさんは評価が甘め、Bさんが少し厳しめであるくらいで、各候補者への評価の高低が全体で一貫している状態です。チーム全体の評価基準の共有がうまくいっており、同じ基準で評価できているからでしょう。
他方、採用チーム2は、4名の回答が一貫していません。全候補者に対して、高得点を付けた人と低得点を付けた人が混在しており、チームメンバーの評価基準がバラバラであることがうかがえます。評価基準が違っているため、4名の評価の平均点は、候補者のどういった特徴の高さが反映されているのか不明です。
この例からわかるように、ある評価基準に基づいて複数名が評価して得点をつける場合、「複数名の評価が一貫していること」は、「評価基準が全体で共有され、同じ基準で評価できていること」と同等なのです。
そして、一貫した評価基準で算出された評価点の平均や合計は、評価基準が捉える特徴の良し悪しをしっかり反映すると考えられます。同じ基準で複数名が評価した得点ならば、それらを平均・合計した得点は、その基準に基づいた得点になっているだろう、ということです。
逆に言えば、複数の評価者が対象を評価する際、その得点が一貫していないと、評価得点の平均や合計が何を意味しているかよくわからない代物になります。
この観点は、複数の質問項目への回答値で一つの概念や事柄を数値化する場合にも適用できます。「ある概念を捉える複数の質問項目において、回答値が一貫していないと、その平均や合計の得点が何を意味するかわからない」ということです。
そのため、因子分析に加えて、各指標への回答値の一貫性を追加で検証する必要があります。では、具体的にどのように信頼性、すなわち得点の一貫性を評価するのでしょう。2つの観点とその検証方法を説明します。
一つは、内部一貫性と呼ばれるものです。これは、先ほど説明した一貫性を指すもので、測定したい概念や事柄を捉える複数の質問項目が一貫していることを表します。
データ分析の上では、複数の質問項目に対してα係数と呼ばれる指標を算出し、その値の高さで評価するのが通例です。心理学では、α係数が.70を超えていれば、十分な信頼性があり回答が一貫していると見なす慣習があります。
α係数が小さいと、複数の質問項目への回答が一貫しておらず、それらを平均・合計した指標の得点が何を意味するかわからないことになります。この問題は、データ分析にも悪影響を及ぼし、それを相関の希薄化と呼びます。

相関の希薄化とは、ある指標のα係数が小さいほど、その指標を用いて算出される相関係数が、本来得られる値と比べて小さくなる現象です。
上の例のように、相関を算出する2つの指標x, yについて、どちらもα=.90と高いα係数が得られ、その状態で2指標の相関係数が.50だったとします。仮に、それぞれの指標のα係数を小さくしていった場合に算出される相関係数を表でまとめています。
この表の数値を見てわかる通り、α係数が小さくなるほど、相関係数が小さくなっていることがわかるでしょう。質問項目への回答が一貫せず信頼性が低い状態になるほど、信頼性が高く測定できたデータと比較して、相関係数が小さくなってしまうのです。
相関係数は、データ分析を用いるその後の検証の要となる指標です。その値が、測定したい概念が本来持つ特徴と無関係な統計学的性質によって小さく算出されるのは問題です。因子分析だけで安心せず、質問項目のα係数がどの程度かを確認しましょう。
もう一つの信頼性の観点として、「継時安定性」と呼ばれるものがあります。これは、同一人物から複数回データを取得した際、ある概念や事柄を表す得点が、複数回の調査間で一貫していることを表します。

例えば、人との交流に積極的で社会的接触を好む傾向である「外向性」のような性格を表す概念は、時間が経過しても、そこまで大きく変わるものではないことが予測されます。ある人の性格が、3か月ごとに変わるような状態は考えにくいでしょう。
時間経過による変化が簡単に生じないと想定される概念や事柄については、それがデータでも成立している、つまり「時間が経っても、得点の高さは一貫している」ことを検証する必要があります。これが継時安定性です。
検証方法としては、ある概念や事柄を測定した指標を、時間を空けて2回測定したデータを準備し、それらの相関係数を見るのが一般的です。相関係数が十分に高ければ、「最初の調査で得点が高かった人は、次の調査でも得点が高い」状態であり、継時安定性があると見なせます。
ある研究では、その相関係数が.70を超えていれば、十分な継時安定性があるとする基準が提案されています(Devon et al., 2007)。
基準連関妥当性と収束的妥当性の検証
ここまでのところで、因子分析と信頼性の検証を行いましたが、これらを経てようやく「複数の質問項目を平均・合計など合算し、ひとつの指標の得点を算出しても問題ない」と示されたことになります。何かの得点を出す際には、回答値を平均して簡単に得点化しがちですが、それをするだけでも様々な検証が必要なのです。
しかし、必要な検証事項はまだあります。ここまでの検証で示されたことは「複数の質問項目を平均・合計など合算して算出された一つの指標の得点が、一つの事柄・概念を表す程度になっていると見なせる」ことまでです。
言い換えると、「その指標の得点が具体的にどのような概念や事柄を表しているのか」という側面は、まだ検証できていないのです。
因子分析において、共通因子は測定したい概念を捉えた要素と説明しました。しかし、実は厳密ではありません。あの時点では、共通因子はまだ複数の質問項目の回答に含まれる共通要素にすぎず、それが何であるかは検証していない状態です。
そこで、ここからは、算出した指標の得点が、どのような概念や事柄を表しているのかを検証していき、指標の得点が本当に狙い通りの概念を捉えたものになっているかを掘り下げていきます。
その検証方法は、組織サーベイの際に、測定したい概念と関連することが予測される、他の指標を追加で測定しておき、それらとの関連をみることです。基準連関妥当性と収束的妥当性と呼ばれるものが有名です[10]。
基準連関妥当性:
測定したい概念や事柄と関連があると予測される、客観的指標との間に十分な関連があると、統計学的に判断できることを指します。
例)仕事へのやる気を測定する指標を作成した場合、仕事にやる気を出して取り組む従業員のパフォーマンスは高いことが想定されます。パフォーマンスに関する客観的指標も追加で取得しておき、仕事へのやる気とパフォーマンス評価の相関をみることで、基準連関妥当性を検証できます。
収束的妥当性:
測定したい概念や事柄と類似したものを測定する指標と十分に関連があると、統計学的に判断できることを指します。
例)新たな仕事へのやる気指標については、既存の有名な概念としてワークエンゲージメントがあります。ワークエンゲージメントの質問項目への回答データも追加で取得し、仕事へのやる気指標とワークエンゲージメントの相関を見ることで、収束的妥当性を検証できます。
ある研究では、基準連関妥当性や収束的妥当性は、相関係数が.45以上あれば、十分な関連があり一定の妥当性が示されたと見なせると述べられています(Devon et al., 2007)。

これらの妥当性検証は、それぞれ一つの指標で想定通りの相関が出て終わり、というものではありません。むしろ、追加指標はいくつ取っても足りないくらいです。先ほど「一定の妥当性が示された」と述べたのは、これで完全に妥当性が実証されたわけではないからです。
とはいえ、妥当性を検証するため一度の調査で追加指標をどんどん増やすと、アンケート全体の量が膨大になり、回答者が疲れてしまいます。それによって回答の質が落ちるのも考え物ですし、協力してくれる回答者に申し訳なくもあります。
そのため、妥当性の検証は、回答者の負担にならない程度に追加指標を入れたり、複数回の調査で様々な妥当性を検証したりして、何度もアプローチを重ねることが求められます。
公平性の検証
最後に、公平性の統計学的な検証について、少し触れておきます。公平性は、「測定したい概念や事柄の特徴と関係しない回答者の属性で、回答が左右されない程度」でした。
データ分析では、それを直接検証していきますが、この検証は現在の研究界隈でも十分に浸透し切っていないような、項目反応理論における特異項目機能の検証や、多母集団同時分析の応用など、高度な分析手法を駆使することが求められます。今回は、分析手法の名称だけ紹介しておきます。
項目反応理論の詳細については、例えば、加藤他(2014)に分析方法が詳しく解説されています。また、田崎(2007)では、文化間比較の文脈で、多母集団同時分析を応用した公平性検証が行われています。興味のある方は、ぜひこれらの文献を読んでみてください。
おわりに
以上のデータ分析による検証を経て、「作成した複数の質問が、測定したい概念や事柄を捉えられていると見なして問題はない」ことが示されました。測定したい概念を測定するには、このような手続きを経る必要があるのです。
解説の内容としては以上になりますが、最後に、個人的な考えをお話ししたいと思います。
心理尺度の作成においては、自分が捉えたい概念や事柄を徹底的に観察し、測定における限界を考えつつも、できる限りそれを純粋に捉える試行錯誤を重ね、取得したデータの正確さを厳しく検証することが求められます。
尺度構成は、人の心理をデータ化して扱う者として、「何を捉えれば良いか」を常に悩み、心理測定上の限界に挑み、それでも足りないことに苦しみ続ける、非常に困難な実践です。今回紹介した手続きは最低限の実践であり、「これで正解、これで終わり」といったものではありません。
今回の紹介をとっかかりに、それぞれの組織サーベイで測定したいものが何かを改めて見つめ直していただけると幸いです。
脚注
[1] 3項目というのは、質問項目数が制限される中で多くの指標を取り上げたい組織サーベイにおいて推奨する項目数です。
[2] 「1つの質問に含まれる複数の内容に強い相関が想定される」場合なら、ダブルバーレルな質問内容の構成でも大きな問題は生じないかもしれません。例えば、「仕事に対して情熱を感じ、日々熱意をもって取り組んでいる」といった質問です。情熱と熱意はほぼ同じ意味であり、これら2つの間には、強い相関があると考えられます。この場合、回答者が「情熱は感じているけど、熱意を持って取り組んでいない」ような混乱が生じる可能性がなく、ダブルバーレルの問題は生じにくくなります。とはいえ、ほぼ同じ意味の語句なら、それらを一緒に盛り込む意義も薄いため、質問内容をシンプルにするために、どちらかの語句のみで質問を作った方が良いとは思います。
[1] 研究上は、既存の有名尺度を用いることも多く見られます。「文中引用の筆者名と出版年で、その尺度の内容を思い出せる」くらいであれば、問題ないかもしれません。しかし、その尺度に改訂があったり、研究独自の文言調整や件法の変更がされたりしている場合もあります。
[2] 逆転項目を入れる積極的理由としては、例えば、黙従傾向(一般に、質問には同意・肯定的な回答をしがちであるバイアス)を解消することが挙げられます。
[3] Well-beingは2側面で捉える枠組みが有名であり(Ryff et al., 2021)、hedonic well-beingは楽しさや満足感といった快楽的な幸福感、eudaimonic well-beingは人生の意味や人間的な成長の実感といった人生哲学的な幸福感をそれぞれ表します。
[4] 確証的因子分析、あるいは、検証的因子分析と呼ばれることもあります。
[5] 「調査への回答時に、上司に褒められる機会が偶然あった」この例は、測定したい概念に関係なく、偶然の要因により回答が違ってくる得点の要素に該当し、正確には偶然誤差と呼びます。
[6] 厳密には、因子分析のモデルでは、共通因子の中に測定したい概念や事柄と関係しない要素が一部含まれています。それは「(偶然に生じるのでなく)回答値に一貫して存在する、測定したい概念や事柄と関係しない要素」であり、系統誤差と呼びます。吉田他(2012)では、この議論を含めて、心理測定に関する様々な解説がコンパクトにまとめられています。
[7] CFI, RMSEAの基準は、Hopwood & Donnellan (2010)を参照しています。
[8] 因子負荷量の正負は分析の内部で方程式を解いた結果であるため、逆転項目の因子負荷量が正で、そうでない項目の因子負荷量が負になることもあります。
[9] なお、「因子モデルに事前の想定なく、複数の質問項目がどのような因子に分かれるか検証したい」場合は、探索的因子分析を用いる方法があります。ここまでの解説では、事前に因子モデルの想定があったため、確認的因子分析で「想定通りにまとまるか」検証していましたが、事前想定無しにどうまとまるか検証する分析手法もあるのです。
[10] 紙幅の都合で割愛しましたが、これらに加えて「弁別的妥当性」も重要です。これは、「測定したい概念や事柄と関連しないと予測される指標との間に、統計学的な関連がみられないこと」を指します。これは、注釈8で述べた系統誤差が、作成した指標の得点にあまり混入していないことを検証しています。測定の純度を高める上で系統誤差を減らすことは重要であり、着手しておきたい検証です。
引用文献
American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. Washington, DC: Joint Committee on Standards for Educational and Psychological Testing.
DeVon, H.A., Block, M.E., Moyle-Wright, P., Ernst, D.M., Hayden, S.J., Lazzara, D.J., et al. (2007). A psychometric toolbox for testing validity and reliability. Journal of Nursing Scholarship, 39, 155-164.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2014). Confirmatory Factor Analysis. In J. F. Hair, R. E. Anderson, R. L. Tatham, & W. C. Black (Eds.) Multivariate data analysis (pp. 599-638). Upper Saddle River, NJ: Prentice Hall.
Hopwood, C. J., & Donnellan, M. B. (2010). How should the internal structure of personality inventories be evaluated? Personality and Social Psychology Review, 14(3), 332-346.
加藤 健太郎・山田 剛史・川端 一光 (2014). Rによる項目反応理論 オーム社
Ryff, C. D., Boylan, J. M., & Kirsch, J. A. (2021). Eudaimonic and hedonic well-being: An integrative Perspective with linkages to sociodemographic factors and health. In. M. T. Lee, L. D. Kubzansky, & T. J. VanderWeele (Eds.), Measuring well-being: Interdisciplinary perspectives from the social sciences and humanities (pp. 92-134). Oxford University Press.
田崎 勝也 (2007). 文化的自己観は本当に「文化」を測っているのかー平均構造・多母集団同時分析を用いた特異項目機能の検証ー 行動計量学, 34(1), 79-89.
吉田 寿夫・石井 秀宗・南風原 朝和(2012). 研究委員会企画チュートリアルセミナー 尺度の作成・使用と妥当性の検証 教育心理学年報, 51, 213-217.
執筆者
 能渡真澄
能渡真澄
株式会社ビジネスリサーチラボ フェロー。信州大学人文学部卒業,信州大学大学院人文科学研究科修士課程修了。修士(文学)。価値観の多様化が進む現代における個人のアイデンティティや自己意識の在り方を、他者との相互作用や対人関係の変容から明らかにする理論研究や実証研究を行っている。高いデータ解析技術を有しており、通常では捉えることが困難な、様々なデータの背後にある特徴や関係性を分析・可視化し、その実態を把握する支援を行っている。



