

2019年5月15日
重回帰分析とは何か(後編)
本コラムでは、近年、HRをテーマにした書籍の中でも取り扱われ始めている「重回帰分析」とは何かを解説します。前編では、重回帰分析の概要を、主に、回帰式の意味について書きました。今回は後編です。
重回帰分析の詳細:分析で出力される指標
前編において、営業スタッフの売上を、転職経験と外向性で予測するという回帰式を例にとりました。これは「転職経験が多いほど、外向性が高いほど、営業売上が高い」という仮説に基づいて組み立てられた方程式です。
上記「営業スタッフの売上予測」の重回帰分析を統計ソフトで行うとします。まず分析対象となるデータを統計ソフトで開き、上記回帰式に基づいて「従属変数 = 営業売上」「独立変数1 = 転職経験」「独立変数2 = 外向性」と指定して分析を実行します。すると、多くの場合、次のような指標が算出されます(あくまでも架空の例です)
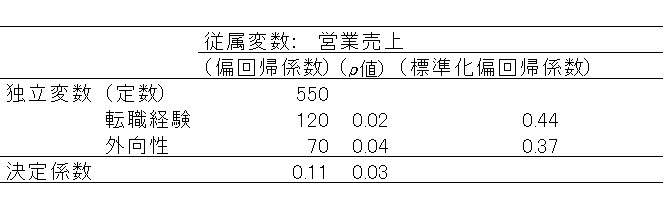
この表の見方ですが、それぞれの独立変数ごとに(ここでは転職経験、外向性)、「偏回帰係数」「p値」「標準化偏回帰係数」という3つの指標が表示されます。またそれとは別に「決定係数」という指標が、独立変数とは別に表示されます。
重要な指標について、順番にその意味や解釈の仕方について考えましょう。
1つめの重要指標は「偏回帰係数」です。これは前編で「係数」と呼んだものの正式名称で、「それぞれの独立変数を何倍すると、従属変数の予測に近づくか」を指す指標です。
上記の例でいえば、「転職経験を120倍して」「外向性を70倍して」、「定数の550を足すと」予測値に近づくといえます。例えば「転職経験3回」「外向性の得点が4点」の社員は「3×120 + 4×70 + 550 = 1190」となるため、おそらく1190万円ほどの売上げをあげうると予測できます(厳密には個人差や誤差も発生します)。
このとき、偏回帰係数が「意味があるほど大きい」のか、「誤差と割り切れるほどばらつきが大きい」のかを示すのが「p値」です。これは過去のコラムで示した「統計的に有意」かどうかを示すものであり、数字が0.05を下回っている場合に、確からしい影響があるといえます。
偏回帰係数の最大の特徴は、「ほかの独立変数の数字が一定と仮定した場合の、当該独立変数の影響の大きさ」を指す点です。例えば、現実には、外向的な人の方が転職経験も多いかもしれません。しかし、この偏回帰係数はそうした可能性を除外して、「(外向性の得点が同じ場合に)転職経験単体が1回増えると営業売上は何円上がるのか?」を計算しています(注1) 。
2つめの重要な指標が「標準化偏回帰係数」です。実は、偏回帰係数には大きな問題があり、特に変数の単位が違う場合に、独立変数間で影響力の大小を比較できません。
今回の例でいえば、外向性の「偏回帰係数」は70ですが、これは「外向性の得点が1点増えると、営業売上が70万円上がる」ことを意味しています。これに対して転職経験の偏回帰係数は120であり、これは「転職経験が1回増えると、営業売上が120万円上がる」ことを意味しています。しかし「外向性の得点が1増えること」と「転職経験が1回増えること」は、同じ「1増える」ことの重大さが異なるため、偏回帰係数を比べて影響力の大小を比較することが困難です。
これに対して、標準化偏回帰係数は独立変数の影響を相互に比較しやすいように、数値の大きさを調整した指標です。今回の例で言えば、転職経験の標準化偏回帰係数は0.44、外向性の標準化偏回帰係数は0.37であるため、両者の影響力の大きさには、偏回帰係数の大きさの違いにみられるほどの、倍近い影響力の差はないと言えます。
最後に、3つめが「決定係数」です。これは通常0~1の範囲を取る指標で、「従属変数のばらつきのうち何%を独立変数で予測できるか」を指しています。
例えば、営業売上は転職経験・外向性だけで決まるのかというと、もちろんそうではありません。それ以外にも、それぞれの社員の知的能力、自社商品への理解度、健康状態、あるいは取引先との相性などの影響も受ける可能性があります。しかし今回の分析は、あくまでも「転職経験と外向性をそれぞれ何倍したら営業売上に近い数字を予測できるか」にとどまるため、当然上記のような他の要因の影響は検出できません。
つまり、分析上は「今回の独立変数だけでは予測しきれない、誤差がたくさんある」と判断されてしまいます。以上の考え方を経て、独立変数によって予測しきれる部分がどれくらいか、逆にいえば誤差(今回の分析では分からない部分)はどれくらいあるかを説明するものが「決定係数」です。
一般的に、人の心理・行動に関する分析ではあまり決定係数は高くならず、せいぜい0.10から0.40程度にとどまる印象です。これを言い換えると「ある人の行動の10%から40%ほどしか予測できない」ということになり、あるいは不十分さを感じる方も多いかもしれません。
しかし、人の心理・行動には文字通りの誤差の部分(例:その日の気分や健康状態、天候などの偶然による要因や、個人差)も多いため、現実にはさほど強固な予測は困難です。例えば工学・経済学に関する分析など、数式で物事を定義しやすい分野と比べると、「100%に近い予測はしづらい」という点には注意が必要です。
まとめ:重回帰分析を用いた例
ここまで、重回帰分析に関する解説をしてきました。内容を箇条書きでまとめると、次のようになります。
- 重回帰分析とは、ある要因の結果を、別の要因で予測する方程式を作る手法のことである。
- 分析にあたって「従属変数」「独立変数」から成る仮説をあらかじめ用意する必要がある。
- 結果は主に「偏回帰係数」「標準化偏回帰係数」「決定係数」から成り、順番に、①独立変数が1点増えると従属変数が何点上がるか、②単位が異なる独立変数間の相対的な影響力の大きさ、③従属変数の現象のどれくらいを説明できるか、を表している。
人事・組織や、幅広く「人」に関するデータ分析の目的は、要因同士のつながりを分析して、ある要因を高めるにはどうすればいいかを導き、実際にその施策を実行するためのヒントを得ることにあります。
そのため、論理的に考えていくと、必然的に「独立変数」「従属変数」と、それらの関連の仕方(回帰式や偏回帰係数)、という考え方に行き当たります。これを定量的に支援するために活用できる最もシンプルな方法のひとつが、重回帰分析なのです (注2)。
(注1)この考え方を応用して、「仮説に直接登場しないが、独立変数に対する影響を排除したい変数を分析に加える」ことがあります(こうした変数のことを「統制変数」と呼びます)。例えば営業売上の例でいえば、転職経験が多いのは必然的に年齢が高い社員になりがちで、例えば20代の社員よりも40代の社員の方が転職経験も多いことが予想されます。そのため、「転職経験が多いほど営業売上が高い」という結果は、本当は「年齢が高い社員の方が営業売上が高い」のかもしれません。こうした別解釈の可能性を排除するために、「年齢」という変数も独立変数として分析に加えることで、「年齢が同じだとした場合に、転職経験の影響はどれくらいか?」を計算させることも可能です。
(注2)これをさらに高度化した方法が、様々な応用的な統計分析の方法や、機械学習であると捉えることもできます。その点において、すべての分析手法の起点になる考え方・手法だ、といっても過言ではないかもしれません。
(了)
執筆者
 正木 郁太郎
正木 郁太郎
2017年東京大学大学院人文社会系研究科博士後期課程修了。博士(社会心理学)。2020年現在、同研究科研究員として在籍。人事・組織に関する研究やHRTech、さらに中等教育などの領域で、民間企業からの業務委託や、アドバイザーなどを複数兼務。組織のダイバーシティに関する研究を中心として、社会心理学や産業・組織心理学を主たる研究領域としており、企業や学校現場の問題関心と学術研究の橋渡しとなることを目指している。著書に『職場における性別ダイバーシティの心理的影響』(東京大学出版会)がある。



